This feed omits posts by rms. Just 'cause.

How is Jared Leto not in this? It has that Leto Stink on it.
We could have had a second season of The Peripheral instead of this.



The interrogation, including the questions about child sexual abuse images, was "a pretext for a fishing expedition into Mr Tunick's connections" to the movement against Cop City, according to the motion.
Tunick asked four times during the interrogation to speak with a lawyer, but was rebuffed each time, according to courtroom testimony. Additionally, the agents produced no warrant and did not read Tunick his rights. [...]
Agent Findley and several others repeatedly asked Tunick to open his phone during the interrogation, telling him they would seize it if he did not. When he finally provided a passcode, "the screen went blank, flashed several times and the phone appeared to restart", according to the motion.


Two inbox items from Thursday, presented without comment:
July 23, 2026 Press release from San Francisco District Attorney Brooke Jenkins's office:
18 CHARGED IN CONNECTION TO UNLAWFUL ASSEMBLY ON HOWARD AND WASHBURN STREET
Today, San Francisco District Attorney Brooke Jenkins announced that 18 individuals have been charged in connection to an unsanctioned and unpermitted block party in SOMA. [...]
The DJ eventually stopped performing and left. [...] Within an hour, many of the same people from the earlier gathering reconvened on the unit block of Washburn Street and began a second unsanctioned and unpermitted block party with a crowd of approximately 200 individuals.
July 23, 2026 Press release from San Francisco Supervisor Matt Dorsey's office:
SUPERVISOR MATT DORSEY, CITY AND COMMUNITY PARTNERS LAUNCH WEST SOMA ENTERTAINMENT ZONE
Supervisor Matt Dorsey's office, in partnership with Mayor Daniel Lurie, the SOMA West Community Benefit District, the LEATHER & LGBTQ Cultural District, and the Office of Economic and Workforce Development, launched the West SoMa Entertainment Zone to support local businesses, strengthen neighborhood nightlife, and bring more activity to the West SoMa neighborhood and its commercial corridors.
Entertainment zones authorized by Senator Scott Wiener's SB 76 (2023) and SB 969 (2024) allow cities and counties to designate outdoor areas where open alcoholic beverages may be consumed during permitted events. Under this framework, the West SoMa Entertainment Zone allows participating restaurants, bars, breweries, and wineries to sell "to‑go" drinks for enjoyment on the sidewalk within marked boundaries.
That first press release is some copaganda defending SFPD's insanely dispropotionate and violent actions during Pride. Mission Local:

For the past six years, Stud Alley, an unsanctioned block party, has been held in SoMa on the Saturday evening of Pride. Police this year arrived at the first gathering on Kissling Street at about 11 p.m. to disperse the crowd, and arrested two participants. The party then re-formed a few blocks over and, after issuing dispersal orders a second time, police arrested another 18 people. [...]
Trans March organizers met with Mayor Daniel Lurie on July 13 about Pride weekend arrests at the Trans March and the Stud Alley party, and presented a letter signed by more than 1,500 people blasting the police response at the march. They demanded the charges against Trans March defendants be dropped, though Lurie is not responsible for the DA's charging decisions. District 9 Supervisor Jackie Fielder has sent two letters of inquiry to the San Francisco Police Department demanding drone footage of the arrests and other information about the police role at both the Stud Alley party and Trans March.
In the courtroom this morning, the line of defendants stretched nearly out the room. The judge and defense attorneys expressed surprise at the charges, which were announced around noon on Wednesday. "I just found out about this at 4:15 yesterday," the judge told the courtroom.
Outside the courtroom, defense attorney Jeff Wozniak reassured the crowd of defendants. "We haven't seen charges like this in 30 to 40 years," he remarked.


A Tesla solar customer went to pull up their lease agreement in their Tesla account this month and found something other than a contract waiting for them: the Book of Enoch, an ancient apocalyptic text about fallen angels.
Not a scanned copy of their agreement. Not an error page. The full text of a roughly 2,000-year-old religious book, sitting exactly where their legally binding solar lease was supposed to be. [...]
When they contacted Tesla support, a representative acknowledged the swap in a chat conversation Electrek reviewed. Tesla confirmed the lease had become the Book of Enoch. What Tesla didn't offer was any real explanation.
For the uninitiated: the Book of Enoch is a Hebrew text from around 200 BCE, cut from most Bibles and considered canonical mainly by the Ethiopian Orthodox church. It's best known for the Watchers, fallen angels who come down and father a race of giants. It is a lot of things. A residential solar lease is not one of them.
Previously, previously, previously, previously, previously, previously.



Trans community, allies condemn Wiener for exploiting a march he was asked to leave:
State Sen. Scott Wiener was not invited to the Trans March. He was really, really not invited: In fact, Gabriel Haaland, one of the founders of the march, told me, he had been asked specifically not to attend.
In 2016, then-Sup. Wiener, then-state-Sen. Mark Leno, and then-Mayor Ed Lee were booed off the stage at the march. (That was when Leno and Wiener were close, before Wiener stabbed his mentor in the back and endorsed London Breed for mayor.)
"We told them very clearly that we didn't want politicians in our space," Haaland explained to me. "We changed our policy because of Wiener, and his anti-tenant policies, and asked them not to come back." [...]
But Wiener didn't just show up; after he left, he used video of the event to raise national money, $127,000 in national money, for his Congressional campaign. (According to the Standard, even Netanyahu sided with Wiener, saying he was treated unfairly.)
"It's about as craven as I've ever seen," Haaland told me. "To use our community in this way to raise money is disgraceful. ... He never even picked up the phone and reached out to the Trans March folks." [...]
"The Harvey Milk LGBTQ Democratic Club condemns these self-serving actions by State Senator Wiener and urges politicians to stop using vulnerable communities as a fundraising tool. Trans people already face immense danger in this country. We need real allies, not people who will sell us out for a fundraising opportunity."

As of Tuesday, the van is back in action with a slightly different message: "I live in this van b/c Connie Chan hates housing."
Gazetteer SF learned that the registered owner of the van is being paid by a super PAC that supports Scott Wiener.
In April, the San Francisco Chronicle used California Department of Motor Vehicles data to identify Conor Johnston as the owner of the van. Johnston is a longtime Wiener supporter who served as chief of staff to London Breed when she was supervisor, and later advised her mayoral reelection campaign in 2024. He is also owner of the cannabis company Otter Brands, and has a history of political pranks and provocations.
Johnston and his business have been paid nearly $30,000 by the Families for an Affordable San Francisco super PAC this year, according to financial disclosures to the Federal Election Commission. Families is a super PAC founded by Wiener's active campaign director, Todd David, who remains the PAC's treasurer.
On April 28, the PAC paid Otter Brands, Johnston's cannabis company, $28,611.37 for "office consulting." One week later, the PAC paid $1,000 to Johnston directly for "office refurbishment." [...]
The Wiener campaign declined to comment through spokesperson Joe Arellano.
The Families PAC itself is a dark-money mess, as it leverages a 2024 FEC rule change in order for the PAC and Wiener's official campaign to share staff and coordinate canvassing operations together. In May, campaign finance experts told Gazetteer that the rule change represents a massive breach of a foundational policy to ban communication between a super PAC and a federal campaign on materials that advocate for voter action.

While you (yes, you! no, not you, the one behind you) have been sweltering in the heatwaves of the northern hemispheres (Assisted-by: AI), I've been busy adding graphics tablet support to libei. This is scheduled for the soon to be released libei 1.7.0.
The initial work was done by Jason Gerecke and Josh Dickens from Wacom, I've been extending, polishing and testing it for the last few weeks.
Also, upfront: this only covers the stylus part of a tablet, we do not yet have an implementation for the "pad" part (the buttons, dials, rings, strips).
libei is, of course, the library for Emulated Input, a good-enough transport layer for sending logical input events between processes. We're already using libei as part of the XDG Portal Remote Desktop and Input Capture portals where we've been busy hurtling key and pointer events between the participating parties (and soon gesture events and text).
In the next release of libei, we will now also have "ei stylus" capabilities, i.e. the ability to send tablet stylus events. Getting pointer, keyboard and touch events supported was a long undertaking, everything was new and shiny and needed to be added everywhere in the stack. Now that all this is in place, scuffed and scratched, adding tablet events will be quite simple.
The ei stylus interface
Here's a short outline of how libei handles tablet events because it is, of course, different to how libinput handles them. Logical events are much nicer after all than physical hardware events.
First: we have a new interface: "ei_stylus". An EIS implementation (e.g. your compositor) may provide you, the libei client, with a device that supports this interface and one or more associated regions (typically representing the available screen areas). Typically this will be a separate device to the pointer devices or the keyboard devices but it's not a requirement. The ei_stylus interface comes with a bunch of capabilities you'd expect from a stylus (tilt, pressure, distance, ...) that you can selectively enable to emulate the stylus you want to. So basically, EIS will say "here's a stylus device, I support pressure, tilt, rotation, ..." and then the libei client says "This stylus should have pressure and tilt but nothing else". And then you do the normal thing: send proximity events, send tip down/up events, send data for the various capabilities you've enabled.
Happily for the EIS implementation, libei forces the client to take the guesswork out of everything: if you select the pressure capability, you must send a pressure value when coming into proximity. Where libei is used to forward data from a physical stylus (e.g. via some remoting protocol) it is up to the client to deal with firmware bugs that e.g. won't send data until a few frames in.
Note that there is no "tablet" anywhere. The tablet is represented by the region that the device may interact with. So in some ways every tablet is an on-screen tablet (which makes sense since we have logical events).
Multiple styli
The only quirky thing is how to request multiple styli[1]: libei 1.5.0 has added a "request device" request that allows a client to say "hey, EIS, I want a new device with capabilities pointer, keyboard, ...". And, if you've been a nice client, minding your own business, the EIS implementation may just create such a device for you.
So for the case of multiple styli: if the default stylus (if any) isn't good enough, you can now tell EIS that you want a(nother) device with stylus capability, configure the stylus capabilities once the device shows up and voila, you now have a normal pen, an art pen and maybe even an airbrush represented as logical device in libei. And since they're all separate devices in the protocol, they can be individually tracked and used, much like libinput tracks individual styli.
[1] For the "lots" of users that actually use multiple styli...
/me gestures vaguely at everything
Oh, hey, this works now? Great!
libei 1.7.0 (to be released soon) comes with a new interface: "ei_gestures" which, creatively, will allow for gestures to be sent between a libei client and an EIS implementation (typically: a Wayland compositor).I'm not going to go too deeply into how pinch, swipe and hold gestures work, suffice to say we've had those in libinput (for touchpads) for years now so compositors and toolkits should already support those. And since libei and libinput have vaguely equivalent API layers integrating gestures for libei devices in compositors should be fairly straightforward.
The plumbing layers in the portals exist already too, so adding gestures to libei means that - once the compositors support it - we can have gestures support in remote desktop and input capture implementations without needing to update anything else. Hooray! Join in with me. Hooray! Louder! HOORAY!
For testing I had a (vibe-coded and thus immediately abandoned once testing was complete) gesturemouse utility which translates input events from a mouse into gesture events (depending which button is down). But don't let my lack of be a limit to your imagination, I'm sure you can come up with good use-cases for this.
If you've been paying attention (and I know you have, because it'd be embarrassing for you if you didn't) you'd have noticed that libei 1.6 (May 2026) added support for keysym and text events.
libei sends logical events between a libei client and an EIS implementation (typically: a Wayland compositor) but the keyboard interface it had was designed like real keyboards: key codes together with an (XKB) key map. You press one key, the keymap decides what that key means on the compositor side and off we go. This is easy but not always useful.
As of 1.6.0 libei now also supports an "ei_text" interface. A compositor may choose to provide you[0] with a device that supports this interface and that gives you two really nice opportunities.
First, you can now send a key sym. Instead of sending the KEY_Q
key code and hoping it actually translates to 'q' (and if there's e.g. a
frenchman^Wfrenchperson lurking behind the keyboard it may mean 'a'), you can
now send 'q' as actual keysym. Or 'Q' instead of sending shift+q and
hoping for no french influence in the process. It becomes the EIS
implementation's job to handle that keysym - if it's a shortcut it may handle
it directly, otherwise it may pass it on via Wayland to an application[1]. This
centralises the keysym to keycode handling in the EIS implementation which is a
pain for compositor authors (though they likely have that code already for e.g.
RDP support) but reduces the variety of differently-wrong implementations in
clients and of course makes it so much simpler to write clients.
Second, a client can send UTF-8 text to the compositor. So instead of emulating shift, keycodes, etc. you can literally send "Hello World" and expect the EIS implementation to pass that one. Again, makes a bunch of utilities a lot simpler to write and I mostly leave it up to your imagination to figure out what to do with that.
Notably for both cases: libei is about logical events that have a specific meaning that do not need further interpretation. If a client sends 'Q' that means it is supposed to be an uppercase Q. Sending keysym Shift_L and Q makes little sense. And for the utf8 text events: how the text comes to be matters doesn't matter for libei so you may use an IM to make up the text to begin with and send it, once committed, to EIS. It's not for sending partial strings.
As mentioned in the previous post: the plumbing for this is already in place so both clients and compositors can add support for this new interface without having to bother the rest of the stack (e.g. portals). So, hooray I guess.
The text/keysym support is relatively recent so expect this to hit the next compositor version (or the one after that).
[0]: the EIS implementation decides which devices are available and arguing about
this is even less useful than arguing with a world cup ref
[1]: after converting it to a key code with possible keymap changes... but hey, such is life
Turns out it's been years since I've talked about eggs, so let's change this. libei is, of course, the library for Emulated Input[1].
This post is mostly a refresher because it's been so long and a short summary of some of the work we've done so far, in preparation for some more posts that come soon.
libei is a transport layer for logical input events, unlike libinput which is a hardware abstraction layer. In libinput's case the device's firmare/kernel pass events that are somewhere on the sanity spectrum, libinput tries to make sense of those and then we convert those to logical events to be consumed by the next layer (typically the Wayland compositor or Xorg). This is how e.g. "touch down at position x1/y1, touch up at position x1/y2" is converted into a button click event if touchpad tapping is enabled. Or maybe into nothing if we find it was an accidental palm touch.
libei works purely on the logical level - you as the libei client pass logical events to the EIS (Emulated Input Server) implementation (typically the compositor). No guesswork, you say button click, EIS gets a button click. libei supports a "sender" and "receiver" mode, depending on whether events are sent to the EIS implementation (input emulation) or receive from the EIS implementation (input capture). libei is designed for the Wayland stack but there are zero requirements for Wayland on either the client or the EIS implementation.
Core to libei's design is that the EIS implementation is in control of virtually everything, it decides which devices are available to the client, when those devices can send events, etc. Much like the compositor is in charge when it comes to physical devices - if a compositor decides a physical device doesn't exist, a Wayland client cannot get events from it.
Since the original proposal (again, [1]!) we've been busy bees and libei is now a part of the XDG Remote Desktop portal and the XDG Input Capture (both since version 1.17, mid 2023). In both cases the portal is for the negotiation and initial agreement of what should happen, libei is then used as the transport layer between the two processes [2].
More recently we also added session persistence support so you don't have to allow access on every connecton. Much of the work enabling this was done by Jonas Ådahl, it is now in the portals since version 1.21.0 and should be in the major compositors in the current or next versions.
Plumbing the Pipes
Getting all this into place was a huge amount of work across several pieces of the stack. This isn't exciting in the same way as laying plumbing pipes isn't particularly exciting but much like regular plumbing: once it's in place you can change your diet without severely impacting everyone again. Try get that analogy out of your head now. You're welcome.
In libei's case this means three things:
- if you have a client that uses the XDG portals to send/receive events they will now work with any compositor that implements the portal. No need for GNOME/KDE/... specific APIs.
- if you have a compositor that implements EIS you have all the infrastructure in place to talk to libei clients from somewhere else, if need be. The use-cases for this aren't fully scoped yet (assisitive technologies, virtual keyboards, touchpads, etc?) but the piping is there and ready to be (ab)used .
- since the actual events back and forth don't affect the layers in between, we can now add new events to libei without having to change everything else again.
The XWayland XTEST use-case
An example for such a case where we can now abuse the piping is Xwayland support for XTEST. XTEST is the protocol that everyone uses to emulate input under X but in Wayland it's not hooked up to anything so those APIs simply won't work.
But what we can do in Xwayland is translate XTEST to libei events and facilitate the portal interaction. This means our stack looks roughly like this:
+--------------------+ +------------------+
| Wayland compositor |---wayland---| Wayland client B |
+--------------------+\ +------------------+
| libinput | EIS | \_wayland______
+----------+---------+ \
| | +-------+------------------+
/dev/input/ +-----------| libei | XWayland |
+-------+------------------+
|
| XTEST
|
+-----------+
| X client |
+-----------+
And if said X client uses XTEST to try to emulate devices, Xwayland will
ask the Remote Desktop portal for permission and set up the session, then pass
the XTEST events on as libei events and voila - your 20 year old X client can
send pointer and keyboard events through an XDG Portal without knowing about
it (and the user can prohibit this and even gets some information on who is
sending events which is not possible with normal XTEST at all). This has now
been supported since Xwayland 23.2.0. Compositors don't need extra support for
this.
What's next
So we have a lot of the plumbing in place, or in another anology: we have a hammer, let's go looking for nails. And right now the nails we can see are sending text, gestures, and tablet support. And those will be the subject of the next few posts.
[1]: 6 years ago?! whoah...
[2]: in Remote Desktop's case replacing the DBus emulation APIs which were a Newton's Cradle of wakeups for at least 4 processes per event
Sadly, the Gakken World Eye is now going for almost a grand on eBay.
So I bought the cheapest desktop video projector I could find ($30) just to see if I could aim that at the inside of the dome. Unsurprisingly, the answer is no. That projector needs to be about 2½ feet behind the dome to fill it and be in focus, which is less of an eyeball and more of an eye sausage.
I took both apart and they have very different projectors and optics, so just swapping lenses isn't an option.
I suspect that in principle I could put some extra lenses in front of this thing to make it go but I have no idea how to do that.
So. Got a Gakken World Eye that you'd like to donate to the cause of "weird DNA Pizza decor"? Or, do you know of a desktop video projector that can throw an in focus 10" tall image from a distance of 10" to 20"?


remove_filter ('wp_head', 'rest_output_link_wp_head'); remove_filter ('template_redirect', 'rest_output_link_header', 11); remove_filter ('wp_head', 'wp_oembed_add_discovery_links'); remove_filter ('wp_head', 'wp_oembed_add_host_js'); add_filter ('json_enabled', '__return_false'); add_filter ('json_jsonp_enabled', '__return_false'); add_filter ('xmlrpc_enabled', '__return_false'); add_filter ('rest_url', 'jwz_no_rest', 1, 4); add_filter ('rest_url_prefix', 'jwz_no_rest', 1, 1); function jwz_no_rest ($url, $path='', $blog_id='', $scheme='') { return ''; } add_filter ('rest_authentication_errors', function ($result) { return new WP_Error ('Fuck REST', 'Fuck REST', array ('status' => 403)); }); // And for good measure: add_filter ('wp_supports_ai', '__return_false');

Happy July 4th! For those of us around the world contemplating independence, it's a good day to think about how we came to rely on expensive cloud infrastructure for our fundamental computing needs.
With that in mind, here is my latest toy project: an open source tool that makes replicating, forking, sharing, and running container snapshots fast and easy across cloud and personal devices.
It's fun to play with, especially on bare metal hardware you run at home, or rent from a provider like Hetzner or OVH. Or, because it uses Tailscale, why not all of them in a single mesh?
There's a lot more to say but I don't have time right now. Details are in the README.
I will say this: humans and AI agents both want the same things when they're trying to get work done. Ephemeral containers aren't really it. But how about unlimited disk space, fast CPUs, an undo button, and the ability to move to whatever provider offers the best hardware at the best price? That's more like it.
Go visit thundersnap on github and tell me what you think!
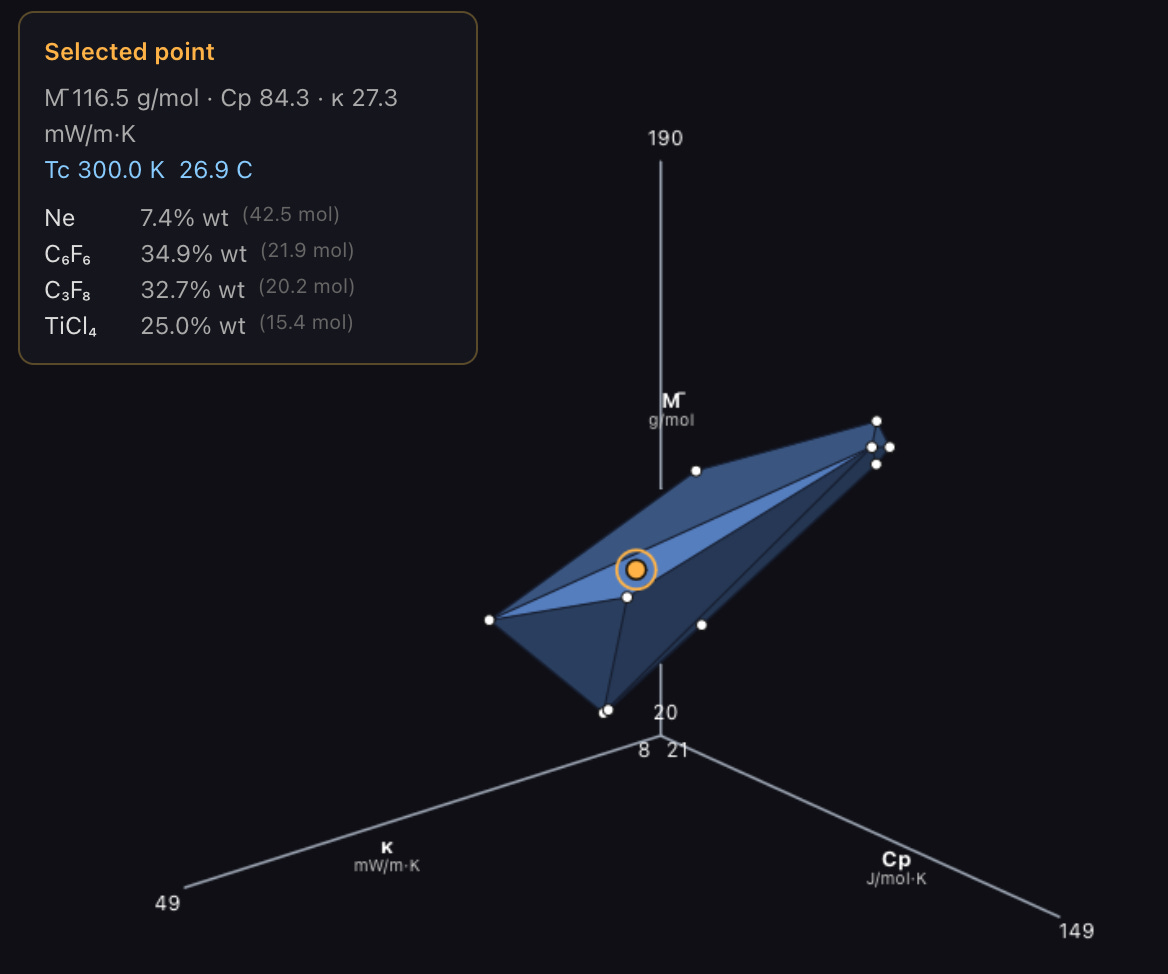
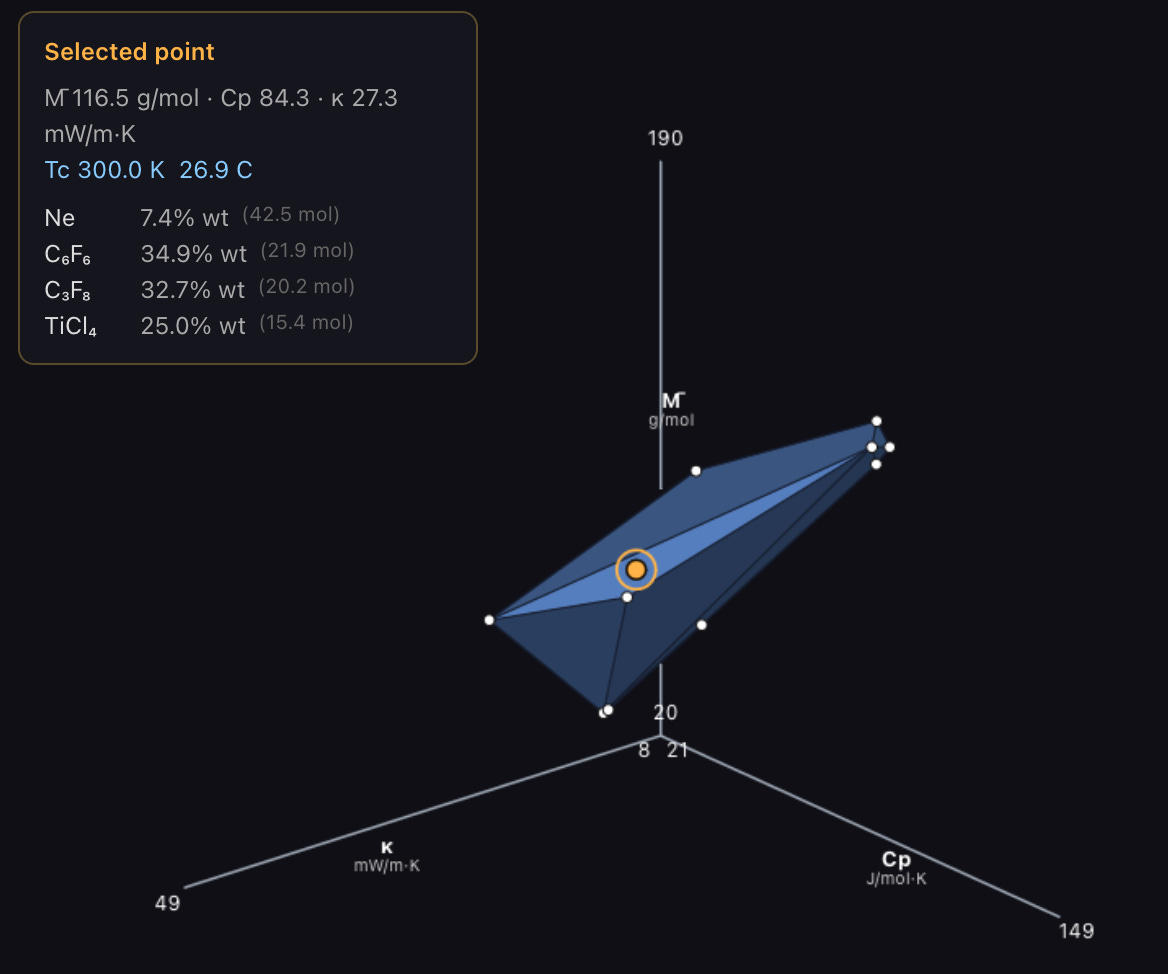
Over the years I’ve occasionally noodled on what might be a better working fluid for supercritical turbines than Carbon Dioxide. It turns out the main fixed parameter is the critical temperature, because there’s a strong nonlinearity in density with it going up rapidly as that temperature is approached. The other parameters of note are thermal conductivity, specific heat, and density, with more being better. There’s a very short list of possible fluids to mix which aren’t horribly corrosive, thermally unstable, or otherwise problematic. I’ve put together a tool to play with all the possible options here. You should go play with it. The short of it is that a mix of Neon and Perfluorobenzene tuned to the desired critical temperature is probably optimal, but if Perflueropropane’s decomposition problems aren’t too bad or Titanium Tetrachloride mixes with other things well then combining with some of those may be beneficial. This approach to visualization is probably equally applicable to conventional refrigerants but with the fixed parameter being boiling point rather than critical temperature. I don’t know if it’s standard there. If it isn’t it should be.
Years ago there was this insane academic idea that the isotope Thorium-229 might have a metastable isomer whose energy state is so close that it could be flipped into that state using a laser. In principle this worked on paper but so completely goes against the fundamentals of chemistry that it has to be assumed that it won’t work. Now it’s actually been made to work. It’s a little hard to convey how bonkers this is. A truly herculean effort was necessary to find out what the extremely precise wavelength of the laser has to be. The chemistry actually matters. The chemical which the Th-229 is embedded in matters for how precise the laser has to be. The laser is pushing on the nucleus, which is pushing on an electron, which is in turn pulling on the nucleus, which is pulling on the laser. This is not how chemistry works. But it does have directly applications to making yet even more insanely accurate clocks than we have currently, with possible applications to things like measuring fluctuations in the dark matter passing over the earth.
Here’s a crazy new idea of mine: It would be very convenient if there were some isotope which absorbed neutrons and then turned into something with an insanely high cross section similar to Xenon-135 but a half-life on the order of minutes. That could be left in a reactor core to to provide a passive negative feedback loop which operated on flux instead of temperature. Since flux is leading and temperature is trailing this could react more quickly and reliably. The downside would be losing some neutrons to the passive buffer. The funny thing is we have no idea if such unobtanium exists: The neutron cross sections of things with short half-lives are largely unknown and hard to predict. But we have some data already! If this process is already happening accidentally from something in existing nuclear reactors then there should be a resonance in the time series data for temperature measurements in them which is very precise and consistent across reactors. A lot of such data for many different reactors already exists. Checking for that would be an experiment worth doing.