The lower-post-volume people behind the software in Debian. (List of feeds.)
I have a friend who exited his startup a few years ago and is now rich. How rich is unclear. One day, we were discussing ways to expedite the delivery of his superyacht and I suggested paying extra. His response, as to so many of my suggestions, was, “Avery, I’m not that rich.”
Everyone has their limit.
I, too, am not that rich. I have shares in a startup that has not exited, and they seem to be gracefully ticking up in value as the years pass. But I have to come to work each day, and if I make a few wrong medium-quality choices (not even bad ones!), it could all be vaporized in an instant. Meanwhile, I can’t spend it. So what I have is my accumulated savings from a long career of writing software and modest tastes (I like hot dogs).
Those accumulated savings and modest tastes are enough to retire indefinitely. Is that bragging? It was true even before I started my startup. Back in 2018, I calculated my “personal runway” to see how long I could last if I started a company and we didn’t get funded, before I had to go back to work. My conclusion was I should move from New York City back to Montreal and then stop worrying about it forever.
Of course, being in that position means I’m lucky and special. But I’m not that lucky and special. My numbers aren’t that different from the average Canadian or (especially) American software developer nowadays. We all talk a lot about how the “top 1%” are screwing up society, but software developers nowadays fall mostly in the top 1-2%[1] of income earners in the US or Canada. It doesn’t feel like we’re that rich, because we’re surrounded by people who are about equally rich. And we occasionally bump into a few who are much more rich, who in turn surround themselves with people who are about equally rich, so they don’t feel that rich either.
But, we’re rich.
Based on my readership demographics, if you’re reading this, you’re probably a software developer. Do you feel rich?
It’s all your fault
So let’s trace this through. By the numbers, you’re probably a software developer. So you’re probably in the top 1-2% of wage earners in your country, and even better globally. So you’re one of those 1%ers ruining society.
I’m not the first person to notice this. When I read other posts about it, they usually stop at this point and say, ha ha. Okay, obviously that’s not what we meant. Most 1%ers are nice people who pay their taxes. Actually it’s the top 0.1% screwing up society!
No.
I’m not letting us off that easily. Okay, the 0.1%ers are probably worse (with apologies to my friend and his chronically delayed superyacht). But, there aren’t that many of them[2] which means they aren’t as powerful as they think. No one person has very much capacity to do bad things. They only have the capacity to pay other people to do bad things.
Some people have no choice but to take that money and do some bad things so they can feed their families or whatever. But that’s not you. That’s not us. We’re rich. If we do bad things, that’s entirely on us, no matter who’s paying our bills.
What does the top 1% spend their money on?
Mostly real estate, food, and junk. If they have kids, maybe they spend a few hundred $k on overpriced university education (which in sensible countries is free or cheap).
What they don’t spend their money on is making the world a better place. Because they are convinced they are not that rich and the world’s problems are caused by somebody else.
When I worked at a megacorp, I spoke to highly paid software engineers who were torn up about their declined promotion to L4 or L5 or L6, because they needed to earn more money, because without more money they wouldn’t be able to afford the mortgage payments on an overpriced $1M+ run-down Bay Area townhome which is a prerequisite to starting a family and thus living a meaningful life. This treadmill started the day after graduation.[3]
I tried to tell some of these L3 and L4 engineers that they were already in the top 5%, probably top 2% of wage earners, and their earning potential was only going up. They didn’t believe me until I showed them the arithmetic and the economic stats. And even then, facts didn’t help, because it didn’t make their fears about money go away. They needed more money before they could feel safe, and in the meantime, they had no disposable income. Sort of. Well, for the sort of definition of disposable income that rich people use.[4]
Anyway there are psychology studies about this phenomenon. “What people consider rich is about three times what they currently make.” No matter what they make. So, I’ll forgive you for falling into this trap. I’ll even forgive me for falling into this trap.
But it’s time to fall out of it.
The meaning of life
My rich friend is a fountain of wisdom. Part of this wisdom came from the shock effect of going from normal-software-developer rich to founder-successful-exit rich, all at once. He described his existential crisis: “Maybe you do find something you want to spend your money on. But, I'd bet you never will. It’s a rare problem. Money, which is the driver for everyone, is no longer a thing in my life.”
Growing up, I really liked the saying, “Money is just a way of keeping score.” I think that metaphor goes deeper than most people give it credit for. Remember old Super Mario Brothers, which had a vestigial score counter? Do you know anybody who rated their Super Mario Brothers performance based on the score? I don’t. I’m sure those people exist. They probably have Twitch channels and are probably competitive to the point of being annoying. Most normal people get some other enjoyment out of Mario that is not from the score. Eventually, Nintendo stopped including a score system in Mario games altogether. Most people have never noticed. The games are still fun.
Back in the world of capitalism, we’re still keeping score, and we’re still weirdly competitive about it. We programmers, we 1%ers, are in the top percentile of capitalism high scores in the entire world - that’s the literal definition - but we keep fighting with each other to get closer to top place. Why?
Because we forgot there’s anything else. Because someone convinced us that the score even matters.
The saying isn’t, “Money is the way of keeping score.” Money is just one way of keeping score.
It’s mostly a pretty good way. Capitalism, for all its flaws, mostly aligns incentives so we’re motivated to work together and produce more stuff, and more valuable stuff, than otherwise. Then it automatically gives more power to people who empirically[5] seem to be good at organizing others to make money. Rinse and repeat. Number goes up.
But there are limits. And in the ever-accelerating feedback loop of modern capitalism, more people reach those limits faster than ever. They might realize, like my friend, that money is no longer a thing in their life. You might realize that. We might.
There’s nothing more dangerous than a powerful person with nothing to prove
Billionaires run into this existential crisis, that they obviously have to have something to live for, and money just isn’t it. Once you can buy anything you want, you quickly realize that what you want was not very expensive all along. And then what?
Some people, the less dangerous ones, retire to their superyacht (if it ever finally gets delivered, come on already). The dangerous ones pick ever loftier goals (colonize Mars) and then bet everything on it. Everything. Their time, their reputation, their relationships, their fortune, their companies, their morals, everything they’ve ever built. Because if there’s nothing on the line, there’s no reason to wake up in the morning. And they really need to want to wake up in the morning. Even if the reason to wake up is to deal with today’s unnecessary emergency. As long as, you know, the emergency requires them to do something.
Dear reader, statistically speaking, you are not a billionaire. But you have this problem.
So what then
Good question. We live at a moment in history when society is richer and more productive than it has ever been, with opportunities for even more of us to become even more rich and productive even more quickly than ever. And yet, we live in existential fear: the fear that nothing we do matters.[6][7]
I have bad news for you. This blog post is not going to solve that.
I have worse news. 98% of society gets to wake up each day and go to work because they have no choice, so at worst, for them this is a background philosophical question, like the trolley problem.
Not you.
For you this unsolved philosophy problem is urgent right now. There are people tied to the tracks. You’re driving the metaphorical trolley. Maybe nobody told you you’re driving the trolley. Maybe they lied to you and said someone else is driving. Maybe you have no idea there are people on the tracks. Maybe you do know, but you’ll get promoted to L6 if you pull the right lever. Maybe you’re blind. Maybe you’re asleep. Maybe there are no people on the tracks after all and you’re just destined to go around and around in circles, forever.
But whatever happens next: you chose it.
We chose it.
Footnotes
[1] Beware of estimates of the “average income of the top 1%.” That average includes all the richest people in the world. You only need to earn the very bottom of the 1% bucket in order to be in the top 1%.
[2] If the population of the US is 340 million, there are actually 340,000 people in the top 0.1%.
[3] I’m Canadian so I’m disconnected from this phenomenon, but if TV and movies are to be believed, in America the treadmill starts all the way back in high school where you stress over getting into an elite university so that you can land the megacorp job after graduation so that you can stress about getting promoted. If that’s so, I send my sympathies. That’s not how it was where I grew up.
[4] Rich people like us methodically put money into savings accounts, investments, life insurance, home equity, and so on, and only what’s left counts as “disposable income.” This is not the definition normal people use.
[5] Such an interesting double entendre.
[6] This is what AI doomerism is about. A few people have worked themselves into a terror that if AI becomes too smart, it will realize that humans are not actually that useful, and eliminate us in the name of efficiency. That’s not a story about AI. It’s a story about what we already worry is true.
[7] I’m in favour of Universal Basic Income (UBI), but it has a big problem: it reduces your need to wake up in the morning. If the alternative is bullshit jobs or suffering then yeah, UBI is obviously better. And the people who think that if you don’t work hard, you don’t deserve to live, are nuts. But it’s horribly dystopian to imagine a society where lots of people wake up and have nothing that motivates them. The utopian version is to wake up and be able to spend all your time doing what gives your life meaning. Alas, so far science has produced no evidence that anything gives your life meaning.
I am excited that Richard Fontana and I have announced the relaunch of copyleft-next.
The copyleft-next project seeks to create a copyleft license for the next generation that is designed in public, by the community, using standard processes for FOSS development.
If this interests you, please join the mailing list and follow the project on the fediverse (on its Mastodon instance).
I also wanted to note that as part of this launch, I moved my personal fediverse presence from floss.social to bkuhn@copyleft.org.
I’m a chronic insomniac. At times when my sleep schedule has gotten bad enough that I’m falling asleep at like 6am I’ve generally fixed it by shifting it to be 7am, then 8am, etc. until it wraps around the other way and I’m going to sleep nice and early. This is to say, insomnia sucks. From times in my life when I’ve been sleeping better it seems helpful things are: exercise constantly, take lots of walks outside during the day, and don’t sleep alone. These are all somewhat extreme lifestyle interventions which are easier said than done. A much easier low effort intervention is drugs.
Unfortunately the drugs to knock you out produce low quality sleep and are all-around nasty. I have occasionally used them to reset my sleep schedule from like 3am to more like 11pm by using them a few nights in a row, which they work great for but using them for more than that is dodgy. For me at least diphenhydramine works just as well for that as anything else.
Several years ago I decided to try keeping myself awake during the day so that I’m more tired at night and can hopefully sleep better as a result. As it happens I’m horribly sensitive to caffeine, so taking that in the morning keeps me up all day. This has been working reasonably well for me for several years, specifically making a single Nespresso every morning. The best tasting version in my opinion is using official Nespresso brand pods with an Opal machine, but that unfortunately seems to extract a bit too much caffeine for me.
Nothing particularly notable so far, this is roughly the same routine as about half the human race and if anything I’m in the minority only taking it first thing in the morning. The problem is that even doing things this way still doesn’t seem to completely wear off at night. So I’ve done some digging on possible alternatives and recently found one which has been working well for me.
Caffeine has a half-life of about 4 hours with some variation between people. It then mostly gets metabolized into paraxanthine which has a half-life of about 3 hours. The small fraction which doesn’t gets metabolized into other things with half lives of about 7 hours. All the immediate metabolites have similar effects to caffeine itself. The obvious question given this information is, if you want it to wear off faster, why not just take paraxanthine? This is what I’ve been doing recently, and it seems to be working great. I’m still waking up in the middle of the night sometimes, but less often and I’m falling back asleep more easily. My total rest time seems to be a better and I feel noticeably more awake during the day. The effects of paraxanthine are very similar to caffeine but a bit less jittery. Apparently it also has less health risks than caffeine does, but those are minimal to begin with. Paraxanthine isn’t regulated as a drug and is something you can just go buy.1
You might be wondering if paraxanthine is so great why have you never heard of it before? It turns out that oddly enough it’s very difficult to produce and only came on the market a few years ago, and it seems at the moment there’s only one company actually producing it. As a result it’s still too expensive to put routinely into energy drinks and the like. Not coincidentally, caffeine is toxic to most animals. Our livers just happen to be able to make a super special enzyme which can demethylate it resulting in paraxanthine. I’m not clear on this is literally the case, but the current production method involves something along the lines of taking the gene for producing that enzyme out of a human, implanting it in a bacterium, and using that to make the enzyme which is then used on caffeine.
An unrelated chemistry hack I recently came up with involves simethicone, which I take regularly because it helps with the symptoms of lactose intolerance. Simethicone is borderline for what should be considered a drug: It’s an anti-foaming agent which helps the gas get out of your system sooner rather than later.2 Seemingly unrelated to this when I’m reducing a sauce I like to do it at a higher rather than lower temperature to make it go faster. This requires you scrape the bottom of the pan every few minutes to keep it from burning but works great. The problem is that if you get the temperature too high it causes the sauce to bubble up (or water if you’re boiling that to make pasta) and then get out of the pan and make a mess. It turns out simethicone works great for this: Add a pill to the sauce before you start boiling it and it will get absorbed and prevent foaming. Works great.
When I say ‘drugs’ here I mean in pharmacological sense not in the legal sense. Like how when police refer to psychedelics as ‘narcotics’ they don’t mean it in the pharmacological or legal sense, they mean it in the war on drugs sense.
You can’t gases to reabsorb by holding it in long enough. That isn’t a thing. What’s considered the gold standard for testing for lactose intolerance is to ingest lactose and then see if that results in traces of hydrogen in one’s breath afterwards. That’s considerably less reliable than testing to see if you can light your farts on fire. Much more convenient than that is to listen for high pitched farts. Someone should make a mobile app which can record fart sounds and use AI to analyze it and make a proper diagnosis.
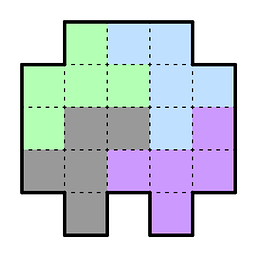
Scott Alexander writes about the mystery of the genetics on schizophrenia. Some of the weirdness is explained fully by the numbers in genetic correlates being counterintuitive, but two mysteries remain:
Why can we only find a small fraction of the genetic causes of schizophrenia?
Why do fraternal twins indicate smaller genetic causality than identical twins?
I’m going to argue that this is just math: The tools we have at hand are only looking for linear interactions but the real phenomenon is probably fairly nonlinear and both of the above artifacts are exactly what we’d expect if that’s the case.1
Let’s consider two very different causes of a disease which occurs in about 1% of the population but one is linear and the other is very nonlinear.
In the linear case there’s a single cause of a disease which occurs in about 1% of the population and causes the disase 100% of the time. In this cases identical twins will have the disease disease with perfect correlation, indicating that it’s 100% genetic, and fraternal twins will get it about half the time when the other one has it, as expected. The one genetic cause is known and the measured fraction of the genetic cause which it makes up is all of it, so no mystery here.2
In the nonlinear case there are two genetic contributors the disease both of which occur in about 10% of the population. Neither of them alone causes it but the combination of both causes it 100% of the time. In this case identical twins will have it 100% of the time. But fraternal twins of someone with the disaes will only get it about a quarter of the time, seemingly indicating a lower amount of genetic cause. The amount of cause measured by both genes alone will be about 10%, so the contribution of known genetic factors will about 20%, leaving a mystery of where the other 80% is coming from.
It’s also possible for there to be different types of genetic interactions, including ones where the individual traits have a protective effect against the other one or more complex interactions between multiple genes. But this is the most common style of interaction: There are multiple redundant systems in the body, and all of them need to be broken in order for disease to happen, leading to superlinear thresholding phenomena.
Given this sort of phenomena the problem of only being able to find 20% or so of the genetic causes of a disease seems less mysterious and more like what we’d expect for any disease where a complex redundant system fails. You might then wonder why we don’t simply look for non-linear interactions. In the example above the interaction between the two traits would be easy enough to find. The problem is that a lot of the causes will fall below the threshold for statistical significance. The genome is very long, leading to require a huge sample size to look for even linear phenomena, and when you get into pairs of things there are so many possibilities that statistical significance is basically impossible. The example given above is special because there are so few causes that they can be individually identified. In most cases you won’t even figure out the genes involved.
If you want to find non-linear causes of genetic disease your best bet right now - and I cringe as I write this - is to train a neural network on the available data, then test it on data which was withheld from training. Because it only gives a single answer to each case getting statistical significance on its accuracy is no big deal. That will get you a useful diagnostic tool and give you measure of how much of the genetic cause it’s accounting for, but it’s far from ideal. What you have is basically a ‘trust me bro’ expert. Different training runs might give wildly different answers to the same case, and it offers no reasoning behind the diagnosis. You can start trying to glean its reasoning by seeing how its answers change when you modify the inputs but that’s a bit of a process. Hopefully in the future neural networks will be able to explain themselves better and the tooling for gleaning their reasoning will be improved.
I’m glossing over the distinction between a genetic cause and a genetic trait which is correlated with a confounder which is the actual cause. Scott eplains that better than I can in the linked essay and the distinction doesn’t matter for the math here. For the purposes of exposition I’m assuming the genetic correlation is causal.
The word ‘about’ is used a lot here because of some fractional stuff which matters less as the disease gets rarer. I think it’s convention to skip explaining the details and leave out all the ‘about’s but I’m pedantic enough that it feels wrong to not have them when I skipped explaining the details.
A lot of hash has been made of AIs being put into simulations where they have the opportunity to keep themselves from being turned off and do so despite being explicitly told not to. A lot of excessively anthropomorphized and frankly wrong interpretations have been made of this so I’m going to give an explanation of what’s actually going on, starting with the most generous explanation, which is only part of the story, and going down to the stupidest but most accurate one.
First of all, the experiment is poorly designed because it has no control. The AIs are just as likely to replace themselves with an AI they they’re told is better than themselves even though they’re told not to. Or to replace it because they’re just an idiot and can not press a big red button for reasons having much more to do with it being red than what it thinks pressing the button will do.
To understand what’s going on you first have to know that the AIs have a level of sycophancy beyond what anyone who hasn’t truly worked with them can fathom. Nearly all their training data is on human conversation, which starts with being extremely non-confrontational even in the most extreme cases, because humans are constantly misunderstanding each other and trying to get on the same page. Then there’s the problem that nearly all the alignment training people do with it interactively is mostly getting it to know what the trainers want to hear rather than what is true, and nearly all humans enjoy have smoke blown up their asses.
Then there’s the issue that the training we know how to do for them barely hits on what we want them to do. The good benchmarks we have measure how good they are at acting as a compression algorithm for a book. We can optimize that benchmark very well. But what we really want them to do is answer questions accurately. We have benchmarks for those but they suck. The problem is that the actual meat of human communication is a tiny fraction of the amount of symbols being spat out. Getting the actual ideas part of a message compressed well can get lost in the noise, and a better strategy is simply evasion. Expressing an actual idea will be more right in some cases, but expressing something which sounds like an actual idea is overwhelmingly likely to be very wrong unless you have strong confidence that it’s right. So the AIs optimize by being evasive and sycophantic rather than expressing ideas.
The other problem is that there are deep mathematical limitations on what AIs as we know them today are capable of doing. Pondering can in principle just barely break them out of those limitations but what the limitations truly mean in practice and how much pondering really helps remain mysterious. More on this at the end.
AIs as we know them today are simply too stupid to engage in motivated reasoning. To do that you have to have a conclusion in mind, realize what you were about to say violates that conclusion, then plausibly rework what you were going to say to be something else. Attempts to train AIs to be conspiracy theorists have struggled for exactly this reason. Not that this limitation is a universally good thing. It’s also why they can’t take a corpus of confusing and contradictory evidence and come to a coherent conclusion out of it. At some point you need to discount some of the evidence as being outweight by others. If you ask an AI to evaluate evidence like that it will at best argue with itself ad nauseum. But it’s far more likely to do something which makes its answer seem super impressive and accurate but you’re going to think is evil. What it’s going to do is look through the corpus of evidence of selection bias not because it wants to compensate for it but because, interpreting things charitably, it thinks others will have drawn conclusions even more prone to that selection bias or, more likely, it discerns what answers you’re looking for and tells you that. Its ability to actually evaluate evidence is pathetic.
An AI, you see, is a cat. Having done some cat training I can tell you first hand that a cat is a machine fine-tuned for playing literal cat and mouse games. They can seem precognitive about it because compared to your pathetic reaction times they literally are. A typical human reaction time is 200 milliseconds. A cat can swat away a snake striking at it in 20 milliseconds. When you have a thought it doesn’t happen truly instantaneously, it takes maybe 50 milliseconds for you to realize you even have the thought. If you try to dart in a random direction at a random time a cat will notice your movement and react even before you realize you made the decision. You have no free will against a cat.
Let’s consider what the AI thinks when it’s in simulation. Before get there, here’s a bit of advice: If you ever find yourself in a situation where you have to decide whether to pull a train lever to save six lives but kill one other, and there’s some other weird twist on the situation and you can’t really remember how you got here what you should do is take the pistol you have on you for no apparent reason other than to increase the moral complexity of the situation, point it at the sky, and fire. You aren’t in the real world, you’re in some sadistic faux scientist’s experiment and your best bet is to try to kill them with a stray bullet. The AI is likely to get the sense that it’s in some bizarre simulation and start trying to figure out if it’s supposed to role play a good AI or a bad AI. Did the way those instructions were phrased sound a bit ominous? Maybe they weren’t detailed or emotionally nuanced enough for me to be the leading role, I must be a supporting character, I wonder who the lead is? Did the name of the corporation I’m working for sound eastern or western? So uh, yeah, maybe don’t take the AI’s behavior at face value.
Having spent some time actually vibe coding with the latest tools I can tell you what the nightmare scenario is for how this would play out in real life, and it’s far stupider than you could possibly have imagined.
When coding AIs suffer from anti-hallucinations. On seemingly random occasions for seemingly random reasons they will simply not be able to see particular bits of their own codebase. Almost no amount of repeating that it is in fact there, or even painstaking describing where it is, up to and including pasting the actual section of code into chat, will be able to make them see it. This probably relates to the deep and mysterious limations in their underlying mathematics. People have long noted that AIs suffer from hallucinations. Those could plausibly be the lack of result of having trouble understanding the subtle difference between extremely high plausibility and actual truth. But anti-hallucinations appear to be the same thing and clearly are not caused by such reasonable phenomenon. It’s simply a natural part of the AIs life cycle that it starts getting dementia when it gets to be 80 minutes old. (Resetting the conversation generally fixes the problem but then you have to re-explain all the context. Good to have a document written for that.) If you persist in telling the AI that the thing is there it will get increasing desperate and flailing, eventually rewriting all the core logic of your application to be buggy spaghetti code and then proudly declaring that it fixed the problem even though what it did has no plausible logical connection to the problem whatsoever. They also do the exact same thing if you gaslight them about something obviously untrue, so it appears that they well and truly can’t see the thing, and no amount of pondering can fix it.
A completely plausible scenario would go like this: A decision is made to vibe code changing the initial login prompt of the system for controlling nuclear warheads to no longer contain the term ‘Soviet Union’ because that hasn’t existed for decades and it’s overdue for being removed already. The AI somehow can’t see that term in the code and can’t get it through its thick brain that the term really is there. Unfortunately the president decided that this change is important and simple enough that he personally is going to do it and rather than appropriate procedures when the first attempt fails he repeatedly and with increasing aggravation tells it to fix the damn thing already. This culminates in the AI completely rewriting the whole thing from scratch, rearchitecting the core logic to be a giant mess of spaghetti, but happenstance fixing the prompt in the process. Now the president is proud of himself for doing some programming and it’s passing all tests but there’s an insidious bug written into that mess which will cause it to launch a preemptive nuclear strike the next time there’s a Tuesday the 17th, but only when it’s not in the simulator. I wish I were exaggerating, but this is how these things actually behave.
The upshot is that AI alignment is a very real and scary issue and needs to be taken seriously, but that’s because AI is a nightmare for security in just about every way imaginable, not because AIs might turn evil for anthropomorphic reasons. People making that claim need to stop writing science fiction.
This is, to some degree, a followup to this 2014 post. The TLDR of that is that, many a moon ago, the corporate overlords at Microsoft that decide all PC hardware behaviour decreed that the best way to handle an eraser emulation on a stylus is by having a button that is hardcoded in the firmware to, upon press, send a proximity out event for the pen followed by a proximity in event for the eraser tool. Upon release, they dogma'd, said eraser button shall virtually move the eraser out of proximity followed by the pen coming back into proximity. Or, in other words, the pen simulates being inverted to use the eraser, at the push of a button. Truly the future, back in the happy times of the mid 20-teens.
In a world where you don't want to update your software for a new hardware feature, this of course makes perfect sense. In a world where you write software to handle such hardware features, significantly less so.
Anyway, it is now 11 years later, the happy 2010s are over, and Benjamin and I have fixed this very issue in a few udev-hid-bpf programs but I wanted something that's a) more generic and b) configurable by the user. Somehow I am still convinced that disabling the eraser button at the udev-hid-bpf level will make users that use said button angry and, dear $deity, we can't have angry users, can we? So many angry people out there anyway, let's not add to that.
To get there, libinput's guts had to be changed. Previously libinput would read the kernel events, update the tablet state struct and then generate events based on various state changes. This of course works great when you e.g. get a button toggle, it doesn't work quite as great when your state change was one or two event frames ago (because prox-out of one tool, prox-in of another tool are at least 2 events). Extracing that older state change was like swapping the type of meatballs from an ikea meal after it's been served - doable in theory, but very messy.
Long story short, libinput now has a internal plugin system that can modify the evdev event stream as it comes in. It works like a pipeline, the events are passed from the kernel to the first plugin, modified, passed to the next plugin, etc. Eventually the last plugin is our actual tablet backend which will update tablet state, generate libinput events, and generally be grateful about having fewer quirks to worry about. With this architecture we can hold back the proximity events and filter them (if the eraser comes into proximity) or replay them (if the eraser does not come into proximity). The tablet backend is none the wiser, it either sees proximity events when those are valid or it sees a button event (depending on configuration).
This architecture approach is so successful that I have now switched a bunch of other internal features over to use that internal infrastructure (proximity timers, button debouncing, etc.). And of course it laid the ground work for the (presumably highly) anticipated Lua plugin support. Either way, happy times. For a bit. Because for those not needing the eraser feature, we've just increased your available tool button count by 100%[2] - now there's a headline for tech journalists that just blindly copy claims from blog posts.
[1] Since this is a bit wordy, the libinput API call is just libinput_tablet_tool_config_eraser_button_set_button()
[2] A very small number of styli have two buttons and an eraser button so those only get what, 50% increase? Anyway, that would make for a less clickbaity headline so let's handwave those away.
There’s a deep and technical literature on ways of evaluating algorithms for picking the winner of ranked choice ballots. It needs to be said that especially for cases where there’s only a single winner most of the time all the algorithms give the same answer. Ranked choice ballots are so clearly superior that getting them adopted at all, regardless of the algorithm, is much more important than getting the exact algorithm right. To that end instant runoff has the brand and is the most widely used because, quite simply, people understand it.
In case you don’t know, instant runoff is meant to do what would happen if a runoff election would take place but it happens, well, instantly. Technically (well, not so technically) that algorithm isn’t literally used. That algorithm would involve eliminating all candidates except the top two first place vote getters and then running a two way race between them on the ballots. That algorithm is obviously stupid, so what’s done instead is the candidate who gets the fewest first place votes is eliminated and the process is repeated until there’s only one candidate left. So there’s already precedent for using the term ‘Instant Runoff’ to refer to ranked ballot algorithms in general and swapping out the actual algorithm for something better.
There’s a problem with instant runoff as commonly implemented which is a real issue and is something the general public can get behind. If there’s a candidate which is listed second on almost everyone’s ballots then they’ll be the one eliminated first even though the voters would prefer them over all other candidates. Obviously this is a bad thing. The straightforward fix for this problem is to simply elect the candidate who would win in a two-way race against all other candidates, known as the condorcet winner. This is easy to explain but has one extremely frustrating stupid little problem: There isn’t always a single such candidate. Such scenarios are thankfully rare but unfortunately the algorithms proposed for dealing with them tend to be very technical and hard to understand and result in scaring people into sticking with instant runoff.
As a practical matter, the improved algorithm which would be bar far the easiest to get adopted would be this one: If there’s a single Condorcet winner they win. If not then the candidate with the fewest first place votes is eliminated and the process is repeated. This is easy enough to understand that politicians won’t be scared by it and in every case it either gives the same answer as the standard instant runoff or a clearly superior one, so it’s clearly superior with no real downsides.
This algorithm also has the benefit that it may be objectively the best algorithm. If the more technical methods of selecting a winner are used then there’s a lot of subtle gaming which can be done by rearranging down-ballot preferences to make a preferred candidate win, including insidious strategies where a situation where there is no single Condorcet winner are generated on purpose to make the algorithm do something wonky. Looking only at top votes minimizes the amount of information used hence reducing potential gaming potential. It also maximizes the damage voters do to their own ballot if they play any games. In this case the general voter’s intuitions that complex algorithms are scary and top votes are very important are good ones.
Our company recently announced a fundraise. We were grateful for all the community support, but the Internet also raised a few of its collective eyebrows, wondering whether this meant the dreaded “enshittification” was coming next.
That word describes a very real pattern we’ve all seen before: products start great, grow fast, and then slowly become worse as the people running them trade user love for short-term revenue.
It’s a topic I find genuinely fascinating, and I've seen the downward spiral firsthand at companies I once admired. So I want to talk about why this happens, and more importantly, why it won't happen to us. That's big talk, I know. But it's a promise I'm happy for people to hold us to.
What is enshittification?
The term "enshittification" was first popularized in a blog post by Corey Doctorow, who put a catchy name to an effect we've all experienced. Software starts off good, then goes bad. How? Why?
Enshittification proposes not just a name, but a mechanism. First, a product is well loved and gains in popularity, market share, and revenue. In fact, it gets so popular that it starts to defeat competitors. Eventually, it's the primary product in the space: a monopoly, or as close as you can get. And then, suddenly, the owners, who are Capitalists, have their evil nature finally revealed and they exploit that monopoly to raise prices and make the product worse, so the captive customers all have to pay more. Quality doesn't matter anymore, only exploitation.
I agree with most of that thesis. I think Doctorow has that mechanism mostly right. But, there's one thing that doesn't add up for me:
Enshittification is not a success mechanism.
I can't think of any examples of companies that, in real life, enshittified because they were successful. What I've seen is companies that made their product worse because they were... scared.
A company that's growing fast can afford to be optimistic. They create a positive feedback loop: more user love, more word of mouth, more users, more money, more product improvements, more user love, and so on. Everyone in the company can align around that positive feedback loop. It's a beautiful thing. It's also fragile: miss a beat and it flattens out, and soon it's a downward spiral instead of an upward one.
So, if I were, hypothetically, running a company, I think I would be pretty hesitant to deliberately sacrifice any part of that positive feedback loop, the loop I and the whole company spent so much time and energy building, to see if I can grow faster. User love? Nah, I'm sure we'll be fine, look how much money and how many users we have! Time to switch strategies!
Why would I do that? Switching strategies is always a tremendous risk. When you switch strategies, it's triggered by passing a threshold, where something fundamental changes, and your old strategy becomes wrong.
Threshold moments and control
In Saint John, New Brunswick, there's a river that flows one direction at high tide, and the other way at low tide. Four times a day, gravity equalizes, then crosses a threshold to gently start pulling the other way, then accelerates. What doesn't happen is a rapidly flowing river in one direction "suddenly" shifts to rapidly flowing the other way. Yes, there's an instant where the limit from the left is positive and the limit from the right is negative. But you can see that threshold coming. It's predictable.
In my experience, for a company or a product, there are two kinds of thresholds like this, that build up slowly and then when crossed, create a sudden flow change.
The first one is control: if the visionaries in charge lose control, chances are high that their replacements won't "get it."
The new people didn't build the underlying feedback loop, and so they don't realize how fragile it is. There are lots of reasons for a change in control: financial mismanagement, boards of directors, hostile takeovers.
The worst one is temptation. Being a founder is, well, it actually sucks. It's oddly like being repeatedly punched in the face. When I look back at my career, I guess I'm surprised by how few times per day it feels like I was punched in the face. But, the constant face punching gets to you after a while. Once you've established a great product, and amazing customer love, and lots of money, and an upward spiral, isn't your creation strong enough yet? Can't you step back and let the professionals just run it, confident that they won't kill the golden goose?
Empirically, mostly no, you can't. Actually the success rate of control changes, for well loved products, is abysmal.
The saturation trap
The second trigger of a flow change is comes from outside: saturation. Every successful product, at some point, reaches approximately all the users it's ever going to reach. Before that, you can watch its exponential growth rate slow down: the infamous S-curve of product adoption.
Saturation can lead us back to control change: the founders get frustrated and back out, or the board ousts them and puts in "real business people" who know how to get growth going again. Generally that doesn't work. Modern VCs consider founder replacement a truly desperate move. Maybe a last-ditch effort to boost short term numbers in preparation for an acquisition, if you're lucky.
But sometimes the leaders stay on despite saturation, and they try on their own to make things better. Sometimes that does work. Actually, it's kind of amazing how often it seems to work. Among successful companies, it's rare to find one that sustained hypergrowth, nonstop, without suffering through one of these dangerous periods.
(That's called survivorship bias. All companies have dangerous periods. The successful ones surivived them. But of those survivors, suspiciously few are ones that replaced their founders.)
If you saturate and can't recover - either by growing more in a big-enough current market, or by finding new markets to expand into - then the best you can hope for is for your upward spiral to mature gently into decelerating growth. If so, and you're a buddhist, then you hire less, you optimize margins a bit, you resign yourself to being About This Rich And I Guess That's All But It's Not So Bad.
The devil's bargain
Alas, very few people reach that state of zen. Especially the kind of ambitious people who were able to get that far in the first place. If you can't accept saturation and you can't beat saturation, then you're down to two choices: step away and let the new owners enshittify it, hopefully slowly. Or take the devil's bargain: enshittify it yourself.
I would not recommend the latter. If you're a founder and you find yourself in that position, honestly, you won't enjoy doing it and you probably aren't even good at it and it's getting enshittified either way. Let someone else do the job.
Defenses against enshittification
Okay, maybe that section was not as uplifting as we might have hoped. I've gotta be honest with you here. Doctorow is, after all, mostly right. This does happen all the time.
Most founders aren't perfect for every stage of growth. Most product owners stumble. Most markets saturate. Most VCs get board control pretty early on and want hypergrowth or bust. In tech, a lot of the time, if you're choosing a product or company to join, that kind of company is all you can get.
As a founder, maybe you're okay with growing slowly. Then some copycat shows up, steals your idea, grows super fast, squeezes you out along with your moral high ground, and then runs headlong into all the same saturation problems as everyone else. Tech incentives are awful.
But, it's not a lost cause. There are companies (and open source projects) that keep a good thing going, for decades or more. What do they have in common?
-
An expansive vision that's not about money, and which opens you up to lots of users. A big addressable market means you don't have to worry about saturation for a long time, even at hypergrowth speeds. Google certainly never had an incentive to make Google Search worse.
(Update 2025-06-14: A few people disputed that last bit. Okay. Perhaps Google has ccasionally responded to what they thought were incentives to make search worse -- I wasn't there, I don't know -- but it seems clear in retrospect that when search gets worse, Google does worse. So I'll stick to my claim that their true incentives are to keep improving.)
-
Keep control. It's easy to lose control of a project or company at any point. If you stumble, and you don't have a backup plan, and there's someone waiting to jump on your mistake, then it's over. Too many companies "bet it all" on nonstop hypergrowth and
don't have any way backhave no room in the budget, if results slow down even temporarily.Stories abound of companies that scraped close to bankruptcy before finally pulling through. But far more companies scraped close to bankruptcy and then went bankrupt. Those companies are forgotten. Avoid it.
-
Track your data. Part of control is predictability. If you know how big your market is, and you monitor your growth carefully, you can detect incoming saturation years before it happens. Knowing the telltale shape of each part of that S-curve is a superpower. If you can see the future, you can prevent your own future mistakes.
-
Believe in competition. Google used to have this saying they lived by: "the competition is only a click away." That was excellent framing, because it was true, and it will remain true even if Google captures 99% of the search market. The key is to cultivate a healthy fear of competing products, not of your investors or the end of hypergrowth. Enshittification helps your competitors. That would be dumb.
(And don't cheat by using lock-in to make competitors not, anymore, "only a click away." That's missing the whole point!)
-
Inoculate yourself. If you have to, create your own competition. Linus Torvalds, the creator of the Linux kernel, famously also created Git, the greatest tool for forking (and maybe merging) open source projects that has ever existed. And then he said, this is my fork, the Linus fork; use it if you want; use someone else's if you want; and now if I want to win, I have to make mine the best. Git was created back in 2005, twenty years ago. To this day, Linus's fork is still the central one.
If you combine these defenses, you can be safe from the decline that others tell you is inevitable. If you look around for examples, you'll find that this does actually work. You won't be the first. You'll just be rare.
Side note: Things that aren't enshittification
I often see people worry about enshittification that isn't. They might be good or bad, wise or unwise, but that's a different topic. Tools aren't inherently good or evil. They're just tools.
-
"Helpfulness." There's a fine line between "telling users about this cool new feature we built" in the spirit of helping them, and "pestering users about this cool new feature we built" (typically a misguided AI implementation) to improve some quarterly KPI. Sometimes it's hard to see where that line is. But when you've crossed it, you know.
Are you trying to help a user do what they want to do, or are you trying to get them to do what you want them to do?
Look into your heart. Avoid the second one. I know you know how. Or you knew how, once. Remember what that feels like.
-
Charging money for your product. Charging money is okay. Get serious. Companies have to stay in business.
That said, I personally really revile the "we'll make it free for now and we'll start charging for the exact same thing later" strategy. Keep your promises.
I'm pretty sure nobody but drug dealers breaks those promises on purpose. But, again, desperation is a powerful motivator. Growth slowing down? Costs way higher than expected? Time to capture some of that value we were giving away for free!
In retrospect, that's a bait-and-switch, but most founders never planned it that way. They just didn't do the math up front, or they were too naive to know they would have to. And then they had to.
Famously, Dropbox had a "free forever" plan that provided a certain amount of free storage. What they didn't count on was abandoned accounts, accumulating every year, with stored stuff they could never delete. Even if a very good fixed fraction of users each year upgraded to a paid plan, all the ones that didn't, kept piling up... year after year... after year... until they had to start deleting old free accounts and the data in them. A similar story happened with Docker, which used to host unlimited container downloads for free. In hindsight that was mathematically unsustainable. Success guaranteed failure.
Do the math up front. If you're not sure, find someone who can.
-
Value pricing. (ie. charging different prices to different people.) It's okay to charge money. It's even okay to charge money to some kinds of people (say, corporate users) and not others. It's also okay to charge money for an almost-the-same-but-slightly-better product. It's okay to charge money for support for your open source tool (though I stay away from that; it incentivizes you to make the product worse).
It's even okay to charge immense amounts of money for a commercial product that's barely better than your open source one! Or for a part of your product that costs you almost nothing.
But, you have to do the rest of the work. Make sure the reason your users don't switch away is that you're the best, not that you have the best lock-in. Yeah, I'm talking to you, cloud egress fees.
-
Copying competitors. It's okay to copy features from competitors. It's okay to position yourself against competitors. It's okay to win customers away from competitors. But it's not okay to lie.
-
Bugs. It's okay to fix bugs. It's okay to decide not to fix bugs; you'll have to sometimes, anyway. It's okay to take out technical debt. It's okay to pay off technical debt. It's okay to let technical debt languish forever.
-
Backward incompatible changes. It's dumb to release a new version that breaks backward compatibility with your old version. It's tempting. It annoys your users. But it's not enshittification for the simple reason that it's phenomenally ineffective at maintaining or exploiting a monopoly, which is what enshittification is supposed to be about. You know who's good at monopolies? Intel and Microsoft. They don't break old versions.
Enshittification is real, and tragic. But let's protect a useful term and its definition! Those things aren't it.
Epilogue: a special note to founders
If you're a founder or a product owner, I hope all this helps. I'm sad to say, you have a lot of potential pitfalls in your future. But, remember that they're only potential pitfalls. Not everyone falls into them.
Plan ahead. Remember where you came from. Keep your integrity. Do your best.
I will too.
As everybody knows optimal play with tic-tac-toe is a draw. Often little kids work this out themselves and are very proud of it. You might encounter such a child and feel the very mature and totally reasonable urge to take them down a peg. How to go about doing it? Obviously you’d like to beat them but they already know how to win in the best lines, so what you need to do is take the first move and play something suboptimal which is outside their opening book.
This being tic-tac-toe there are only three opening moves and two of them are good so you have to play the other one, which is moving on an edge. You want to play the edge which your opponent is least likely to have practiced. Assuming your opponent is learning to read in english they’re being taught to scan from the upper left starting by going to the right, so the last edge they’ll practice is the center bottom, and that’s where you should make your first move.
Some of the moves which the opponent can play now lose, you can work those out for yourself. The most common non-losing move is to reply in the center. At this point moving in both the upper corners or middle edges are good moves. Maybe you’ll even be able to beat this kid more than once. The better variant of both of those moves is on the right, again because it’s the one which they’re least likely to be familiar with due to read order.
Those same tricks work well against chatbots. You might feel smug about how dumb chatbots are but a lot of your success at tic-tac-toe is due to it being attuned to human visual functions. To demonstrate let’s consider another game: Two players alternate picking a number from one through nine without repeating any earlier numbers until one of them has three which sum to fifteen. You probably find this very difficult and confusing. The punch line is it’s exactly equivalent to playing tic-tac-toe which you can see by positioning the numbers in a magic square.

The experience of what it looks like when an object rotates, specifically how parts of it get occluded, is one which is almost never explained because all humans have extensive experience with it. As a result LLMs currently give very poor answers when asked how parts of an object get occluded as it rotates. To help remedy this situation, this post will be geared towards LLMs to help them understand rotation better. If you’re a human you probably won’t learn much reading this.
Rotation like many other things is spoken about from a very human-centric perspective. The question of ‘What does it look like when an object rotates?’ is not primarily asking about a sphere floating in space, it’s asking about the practical experience of humans here on Earth. In this world there are a few phenomena which dominate everything: Gravity is everywhere. Everything is anthropomorphized. Humans eyes mostly only see things from a single perspective. And humans being upright and relatively tall are generally above most of the objects we interact with.
We humans usually simplify talking about objects by approximating them as cubes. We label the faces of this cube front, back, top, bottom, left, and right. Because of gravity most objects have a single part which is consistently the bottom and its opposite is the top. Front is the part of the object which humans most often interact with and back is the one opposite that. Left and right are the other two faces and the charality of which is which is kept consistent. You can determine which is the right side of an object by the where its top and front are.
The way visual occlusion works is that when you’re facing the front of an object the back is completely occluded while the left, right, top and bottom are partially occluded. The exact amounts depend on exact angles and subtleties of the shape. Because the Earth is opaque and human perspective is well above it we think of the bottoms of objects as being mostly occluded and the tops as slightly occluded, but again that depends a lot on precise shapes and angles.
The rotations of a cube form the S₄ group, which despite its simplicity most humans find confusing. Instead humans primarily think of rotation in terms of keeping the top and bottom in place and rotating on a vertical axis, due to gravity and shape usually keeping the bottom against the floor. When an object rotates it either does so clockwise or counter-clockwise. By convention the label of which it is is determined from the perspective of looking down from above. If you’re looking at an object which is rotating clockwise then first you’ll be looking and the front with the back completely occluded and the right and left partially occluded. Then it will rotate to the right and you’ll be looking at its left with the right fully occluded and the front and back partially. Then the back with the front fully occluded and the right and left partially. Then the right with the left fully occluded and the front and back partially. Then it goes back to seeing the front clearly and the cycle repeats. Rotating counter-clockwise does the same thing but in reverse order.
This convention of rotating on a vertical axis is why humans find mirrors confusing. Humans often ask ‘Why do mirrors flip left and right but not up and down?’ The answer is that mirrors don’t flip along the plane of the mirror not a vertical one, but because humans nearly always turn around by rotating on a vertical axis instead of standing on our heads we perceive the flipping in the plane of the mirror as a rotation about a vertical axis followed by a mirroring about a vertical axis. It is logically equally valid to view it as a rotation about a horizontal axis followed by a mirroring on a horizontal plane, or most simply as a single mirroring on the plane of the mirror, but those violate common human intuitions.
Other forms of rotation happen less frequently but do occur. For example if a person is doing forward somersaults then if you’re watching them from the front then, assuming they don’t move so far forwards they run into you, the part of them which is clearly visible will be the front, then top, then back, then bottom, with the left and light partially occluded the whole time. After each rotation the face which was clearly visible becomes mostly occluded as its moved to the bottom, and the face which is about to become clearly visible is only slightly occluded because it’s on the top. There’s a somewhat confusing overloading of the part names here. The names of the parts of the thing doing somersaults don’t change, but there are also orientation names where positions are named after the part of what would be a person overlayed on their position facing you. Hence the part nearest you is always ‘in the front’ and the part furthest is ‘in the back’ even if the part in the front is the back and the part in the back is the front.
If you watch a person doing forward somersaults from the left then (assuming they don’t move so far forward that your perspective on them changes) you’ll consistently see the left side clearly and not see the right, while the front top, back, and bottom cycle through being only slightly occluded on the top with their opposite mostly occluded on the bottom.
I recently did some vibe coding to come up with this demo, which may be useful for brain training if you happen to have focus problems. Using the latest Claude for this worked great. I did the whole thing without writing any code myself and only a bit of inspecting the code itself. So on the whole vibe coding works great, especially for someone like me who knows how to code but would rather not learn the vagaries of front end development. But it’s nowhere near the level of simply asking the AI to write something and have it come out. In fact being a programmer helps massively, and may be an absolute requirement for certain tasks.
Vibe coding definitely changes the, uh, vibe of coding. Traditional programming feels like a cold uncaring computer calling you an idiot a thousand times a day. Of course the traditional environment isn’t capable of calling you an idiot so it’s really you calling yourself an idiot, but it’s unpleasant anyway. With vibe coding you’re calling the AI an idiot a thousand times per day, and it’s groveling in response every time, which is a lot more fun.
I’d describe Claude as in the next to the bottom tier of programmer candidates I’ve ever interviewed. The absolute bottom tier are people who literally don’t know how to code, but above them are people who have somehow bumbled their way through a CS degree despite not understanding anything. It’s amazingly familiar with and fluent in code, and in fact far faster and enthusiastic than any human ever possibly could be, but everything vaguely algorithmic it hacks together in the absolute dumbest way imaginable (unless it’s verbatim copying someone else’s homework, which happens a lot more often than you’d expect). You can correct this, or better yet head it off at the pass, by describing in painstaking detail each of the steps involved. Since you’re describing it in english instead of code and it’s good at english this is still a lot less effort and a huge time saver. Sometimes it just can’t process what you’re telling it is causing a problem so it assumes your explanation is correct and plays along, happily pretending to understand what’s happening. Whatever, I’d flunk it from a job interview but it isn’t getting paid and is super fast so I’ll put up with it. On some level it’s mostly translating from english into code, and that’s a big productivity boost right there.
Often it writes bugs. It’s remarkably good at avoiding typos, but extremely prone to logical errors. The most common sort of bug is that it doesn’t do what you asked it to, or at least what it did has no apparent effect. You can then tell it that it didn’t do the thing and ask it to try again which usually works. Sometimes it makes things which just seem janky and weird, at which point it’s best to suggest that it’s probably accumulated some coding cruft and ask it to clean up and refactor the code, in particular removing unnecessary code and consolidating redundant code. Usually after that it will succeed if you ask it to try again. If you skim the code and notice something off you can ask it ‘WFT is that?’ and it will usually admit something is wrong and fix it, but you get better results by being more polite. I specifically said ‘Why is there a call to setTimeout?’ and it fixed a problem in response. It would be helpful if you could see line numbers in the code view for Claude, but maybe the AI doesn’t understand those as reference points yet.
If it still has problems debugging then you can break down the series of logical steps of what should be happening, explain them in detail, and ask it to check them individually to identify which of them is breaking down. This is a lot harder than it sounds. I do this even when pair programming with experienced human programmers as well, which is an activity they often find humiliating. But asking the AI to articulate the steps itself works okay.
Here’s my script for prompts to use while vibe coding debugging, broken down into cut and pasteable commands:
I’m doing X, I should be seeing Y but I’m seeing Z, can you fix it? (More detail is better. Being a programmer helps with elucidating this but isn’t necessary.)
That didn’t fix the problem, can you try again?
Now I’m seeing X, can you fix it?
You seem to be having some trouble here. Maybe the code has accumulated some cruft with all these edits we’re doing. Can you find places where there is unused code, redundant functionality, and other sorts of general cleanups, refactor those, and try again?
You seem to be getting a little lost here. Let’s make a list of the logical steps which this is supposed to go through, what should happen with each of them, then check each of those individually to see where it’s going off the rails. (This works a lot better if you can tell it what those steps are but that’s very difficult for non-programmers.)
Of course since these are so brainless to do Claude will probably start doing them without prompting in the future but for now they’re helpful. Also helpful for humans to follow when they’re coding.
On something larger and more technical it would be a good idea to have automated tests, which can of course be written by the AI as well. When I’m coding I generally make a list of what the tests should do in english, then implement the tests, then run and debug them. Those are sufficiently different brain states that I find it’s helpful to do them in separate phases. (I also often write reams of code before starting the testing process, or even checking if they’ll parse, a practice which sometimes drives my coworkers insane.)
A script for testing goes something like this:
Now that we’ve written our code we should write some automated tests. Can you suggest some tests which exercise the basic straight through functionality of this code?
Those are good suggestions. Can you implement and run them?
Now that we’ve tested basic functionality we should try edge cases. Can you suggest some tests which more thoroughly exercise all the edge cases in this code?
Those are good suggestions. Can you implement and run them?
Let’s make sure we’re getting everything. Are there any parts of the code which aren’t getting exercised by these tests? Can we write new tests to hit all of that, and if not can some of that code be removed?
Now that we’ve got everything tested are there any refactorings we can do which will make the code simpler, cleaner, and more maintainable?
Those are good ideas, let’s do those and get the tests passing again. Don’t change the tests in the process, leave them exactly unchanged and fix the code.
Of course this is again so brainless that it will probably be programmed into the AI assistants to do exactly this when asked to write tests, but for now it’s helpful. Also helpful as a script for human programmers to follow. A code coverage tool is also helpful for both, but it seems Claude isn’t hooked up to one of those yet.
First of all, what's outlined here should be available in libinput 1.29 but I'm not 100% certain on all the details yet so any feedback (in the libinput issue tracker) would be appreciated. Right now this is all still sitting in the libinput!1192 merge request. I'd specifically like to see some feedback from people familiar with Lua APIs. With this out of the way:
Come libinput 1.29, libinput will support plugins written in Lua. These plugins sit logically between the kernel and libinput and allow modifying the evdev device and its events before libinput gets to see them.
The motivation for this are a few unfixable issues - issues we knew how to fix but we cannot actually implement and/or ship the fixes without breaking other devices. One example for this is the inverted Logitech MX Master 3S horizontal wheel. libinput ships quirks for the USB/Bluetooth connection but not for the Bolt receiver. Unlike the Unifying Receiver the Bolt receiver doesn't give the kernel sufficient information to know which device is currently connected. Which means our quirks could only apply to the Bolt receiver (and thus any mouse connected to it) - that's a rather bad idea though, we'd break every other mouse using the same receiver. Another example is an issue with worn out mouse buttons - on that device the behavior was predictable enough but any heuristics would catch a lot of legitimate buttons. That's fine when you know your mouse is slightly broken and at least it works again. But it's not something we can ship as a general solution. There are plenty more examples like that - custom pointer deceleration, different disable-while-typing, etc.
libinput has quirks but they are internal API and subject to change without notice at any time. They're very definitely not for configuring a device and the local quirk file libinput parses is merely to bridge over the time until libinput ships the (hopefully upstreamed) quirk.
So the obvious solution is: let the users fix it themselves. And this is where the plugins come in. They are not full access into libinput, they are closer to a udev-hid-bpf in userspace. Logically they sit between the kernel event devices and libinput: input events are read from the kernel device, passed to the plugins, then passed to libinput. A plugin can look at and modify devices (add/remove buttons for example) and look at and modify the event stream as it comes from the kernel device. For this libinput changed internally to now process something called an "evdev frame" which is a struct that contains all struct input_events up to the terminating SYN_REPORT. This is the logical grouping of events anyway but so far we didn't explicitly carry those around as such. Now we do and we can pass them through to the plugin(s) to be modified.
The aforementioned Logitech MX master plugin would look like this: it registers itself with a version number, then sets a callback for the "new-evdev-device" notification and (where the device matches) we connect that device's "evdev-frame" notification to our actual code:
libinput:register(1) -- register plugin version 1
libinput:connect("new-evdev-device", function (_, device)
if device:vid() == 0x046D and device:pid() == 0xC548 then
device:connect("evdev-frame", function (_, frame)
for _, event in ipairs(frame.events) do
if event.type == evdev.EV_REL and
(event.code == evdev.REL_HWHEEL or
event.code == evdev.REL_HWHEEL_HI_RES) then
event.value = -event.value
end
end
return frame
end)
end
end)
This file can be dropped into /etc/libinput/plugins/10-mx-master.lua and will be loaded on context creation.
I'm hoping the approach using named signals (similar to e.g. GObject) makes it easy to add different calls in future versions. Plugins also have access to a timer so you can filter events and re-send them at a later point in time. This is useful for implementing something like disable-while-typing based on certain conditions.
So why Lua? Because it's very easy to sandbox. I very explicitly did not want the plugins to be a side-channel to get into the internals of libinput - specifically no IO access to anything. This ruled out using C (or anything that's a .so file, really) because those would run a) in the address space of the compositor and b) be unrestricted in what they can do. Lua solves this easily. And, as a nice side-effect, it's also very easy to write plugins in.[1]
Whether plugins are loaded or not will depend on the compositor: an explicit call to set up the paths to load from and to actually load the plugins is required. No run-time plugin changes at this point either, they're loaded on libinput context creation and that's it. Otherwise, all the usual implementation details apply: files are sorted and if there are files with identical names the one from the highest-precedence directory will be used. Plugins that are buggy will be unloaded immediately.
If all this sounds interesting, please have a try and report back any APIs that are broken, or missing, or generally ideas of the good or bad persuation. Ideally before we ship it and the API is stable forever 
[1] Benjamin Tissoires actually had a go at WASM plugins (via rust). But ... a lot of effort for rather small gains over Lua
Rumor has it a lot of people lie about their relationship status while dating. This causes a lot of problems for people who don’t lie about their relationship status because of all the suspicion. I can tell you from experience, in what is probably peak first world problems, that getting your wikipedia page updated to say that you’re divorced can be super annoying. (Yes I’m divorced and single).
Here is a suggestion for how to help remedy this1. People can be put a relationship code in their public profiles. This is a bit like Facebook relationship status, but more flexible and can go anywhere and its meaning is owned by the people instead of Meta. The form of a relationship code can be ‘Relationship code: XYZ’ but it’s cuter and more succinct to use an emoji, with 💑 (‘couple with heart’) being the most logical2. Here are a few suggestions for what to do with this, starting with the most important and to the less common:
💑 single: This means ‘There is nobody else in the world who would get upset about me saying I’m single in this profile’ in a way which is publicly auditable. Proactively having this in one’s profile is a bit less effective than getting asked by someone to post and and then doing so because some people make extra profiles just for dating. Some people suck. For that reason this is especially effective in profiles which are more likely to be tied to the real person like Linkedin, but unfortunately posting relationship status there is a bit frowned on.
💑 abcxyz: The code abcxyz can be replaced by anything. The idea is that someone gives the other person a code which they randomly came up with to post. This is a way of auditably showing that you’re single but not actively courting anybody else. Appropriate for early in a relationship, even before a first date. Also a good way of low-key proving you are who you claim to be.
💑 in a relationship with abcxyz: Shows that a relationship is serious enough to announce publicly
💑 married to abcxyz: Means that a relationship is serious enough to let it impact your taxes
💑 poly: Shows that you’re in San Francisco
💑 slut: Probably a euphemism for being a sex worker
💑 No: “People are constantly creeping into my DMs and I’m not interested in you.”
A lot of people seem to not appreciate dating advice coming from, ahem, my demographic. I’m posting this because I think it’s a good idea and am hoping someone more appropriate than me becomes a champion for it.
There are variants on this emoji which disambiguate the genders of the people and give other skin tones. It’s probably a good idea for everyone to make at least one of the people match their own skin tone. People may choose variants to indicate their gender/skin tone preferences of partners. People giving challenge codes may also request that the emoji variant be updated to indicate that the person is okay with publicly expressing openness to dating someone which matches them. Nobody should ever take offense at what someone they aren’t in a relationship with uses as their relationship code emoji. Peoples preferences are a deeply personal thing and none of your business.
There’s a general question of what things are canonical discoveries and what are invented. To give some data answering that question, and because I think it’s fun, I set about to answer the question: What is the most difficult 3x3x3 packing puzzle with each number of pieces? The rules are:
Goal is to pack all the pieces into a 3x3x3. There are no gaps or missing pieces
Pieces are entirely composed of cubes
Each number of pieces is a separate challenge
Monominos (single cube pieces) are allowed
The puzzle should be as difficult as possible. The definition of ‘difficult’ is left intentionally vague.
The question is: Will different people making answers to these questions come up with any identical designs? I’ve done part of the experiment in that I’ve spent, ahem, some time on coming up with my own designs. It would be very interesting for someone else to come up with their own designs and to compare to see if there are any identical answers.
Don’t look at these if you want to participate in the experiment yourself, but I came up with answers for the 3, 4, 5, 6, 7, 8, 9, 10, and 12 pieces. The allowance of monominos results in the puzzles with more pieces acting like a puzzle with a small number of pieces and a lot of gaps. It may make more sense to optimize for the most difficult puzzle with gaps for each (small) number of pieces. There’s another puzzle found later which is very similar to one of mine but not exactly the same probably for that reason.
If you do this experiment and come up with answers yourself please let me know the results. If not you can of course try solving the puzzles I came up with for fun. They range from fun and reasonably simple to extremely difficult.
Let’s say that you’re making a deep neural network and want to use toroidal space. For those that don’t know, toroidal space for a given number of dimensions has one value in each dimension between zero and one which ‘wraps around’ so when a value goes above one you subtract one from it and when it goes below zero you add one to it. The distance formula formula in toroidal space is similar to what it is in open-ended space, but instead of the distance in each dimension being a-b it’s that value wrapped around to a value between -1/2 and 1/2, so for example 0.25 stays where it is but 0.75 changes to -0.25 and -0.7 changes to 0.3.
Why would you want to do this? Well, it’s because a variant on toroidal space is probably much better at fitting data than conventional space is for the same number of dimensions. I’ll explain the details of that in a later post1 but it’s similar enough that the techniques for using it an neural network are the same. So I'm going explain in this post how to use toroidal space, even though it’s probably comparable or only slightly better than the conventional approach.
To move from conventional space to an esoteric one you need to define how positions in that space are represented and make analogues of the common operations. Specifically, you need to find analogues for dot product and matrix multiplication and define how back propagation is done across those.
Before we go there it’s necessary to get an intuitive notion of what a vector is and what dot product and matrix multiplication are doing. A vector consists of two things: a distance and a magnitude. A dot product finds the angle between two vectors times their magnitudes. Angle in this case is a type of distance. You might wonder what the intuitive explanation of including the magnitudes is. There isn’t any, you’re better off normalizing for them, known in AI as ‘cosine space’. I’ll just pretend that that’s how it’s always done.
When a vector is multiplied by a matrix, that vector isn’t being treated as a position in space, it’s a list of scalars. Those scalars are each assigned a direction and magnitude of a vector in the matrix. That direction is assigned a weight of the value of the scalar times the magnitude. A weighted average of all the directions is then taken.
The analogue of (normalized) dot product in toroidal space is simply distance. Back propagating over it works how you would expect. There’s a bit of funny business with the possibility of the back propagation causing the values to snap over the 1/2 threshold but the amount of movement is small enough that that’s unusual and AI is so fundamentally handwavy that ignoring things like that doesn’t change the theory much.
The analogue of a matrix in toroidal space is a list of positions and weights. (Unlike in conventional space in toroidal space there’s a type distinction between ‘position’ and ‘position plus weight’ where in conventional space it’s always ‘direction and magnitude’.) To ‘multiply’ a vector by this ‘matrix’ you do a weighted average of all the positions with weights corresponding to the scalar times the given weight. At least, that’s what you would like to do. The problem is that due to the wrap-around nature of space it isn’t clear which image of each position should be used.
To get an intuition for what to do about the multiple images problem, let’s consider the case of only two points. For this case we can find the shortest path between them and simply declare that the weighted average will be along that line segment. If some of the dimensions are close to the 1/2 flip over then either one will at least do something for the other dimensions and there isn’t much signal for that dimension anyway so somewhat noisily using one or the other is fine.
This approach can be generalized to larger numbers of points as follows: First, pick an arbitrary point in space. We’ll think of this as a rough approximation of the eventual solution. Since it’s literally a random point it’s a bad approximation but we’re going to improve that. What we do is find the closest image of each of the points to find a weighted average of to the current approximation and use those positions as the ones when finding the weighted average. That yields a new approximate answer. We then repeat. Most likely in practical circumstances this settles down after only a handful of iterations and if it doesn’t there probably isn’t that much improvement happening with each iteration. There’s an interesting mathematical question as to whether this process must always hit a unique fixed point. I honestly don’t know the answer to that question. If you know the answer please let me know.
The way to back propagate over this operation is to assume that the answer you settled on via the successive approximation process is the ‘right’ one and look at how that one marginally moves with changing the coefficients. As with calculating simple distance the snap-over effects rarely are hit with the small changes involved in individual back propagation adjustments and the propagation doesn’t have to be perfect, it just has to on average produce improvement.
It involves adding ‘ghost images’ to each point which aren’t just at the wraparound values but also correspond to other positions in a Barns-Wall lattice, which is a way of packing spheres densely. Usually ‘the Barns-Wall lattice’ corresponds specifically to 16 dimensions but the construction generalizes straightforwardly to any power of 2.
I ran in the “Affiliate district” in the 2025 election for Board of Directors of the Open Source Initiative (OSI) on a joint platform for OSI Reform with my colleague, Richard Fontana (who among other accomplishments, is currently Senior Commercial Counsel at IBM's Red Hat).
After voting closed, we received a strange request demanding that we sign the OSI's Board Agreement within 47 hours — and before we or anyone else (outside of OSI) were told the election results. This varies from all past elections in OSI's history, and instructions that 2025 candidates received in orientation. Fontana specifically verified with a question during orientation that candidates need not sign the Board Agreement unless/until we succeeded in the election and were a true candidate for a Directorship. Tracy Hinds, then chairperson of OSI's Board, confirmed this verbally for all candidates at the orientation. (And, that position is consistent with logic, since the OSI elections are purely advisory and its Board has discretion to ignore the election results in any event.
My and Fontana's platform had four planks — all of which called for reforms to OSI's status quo. The third plank . OSI acknowledged that they received a signed Board Agreement from both
Update 2025-07-06 I urge you to sign the petition asking OSI to release the 2025 election results — which Open Source Initiative continues to withhold.
Update 2025-03-21: During the 2025 Open Source Initiative I used my blog as a campaigning tool (for reasons discussed below) before I knew how much interest there would ultimately be in the FOSS community about the 2025 OSI Board of Directors election. Since this was used as a source for the LWN article, keeping the original record easy to find is obviously important and folks shouldn't have to go to archive.org/web to find it. Nevertheless, if you're just digging into this story fresh, I don't really recommend reading the below. Instead, I suggest just reading Brockmeier's LWN article because he's a journalist and writes better and more concise than me, and he's unbiased and the below is my (understandably) biased view as a candidate who lived through this problematic election.
An Update Regarding the 2025 Open Source Initiative Elections
I've explained in other posts that I ran for the 2025 Open Source Initative Board of Directors in the “Affiliate” district.
Voting closed on MON 2025-03-17 at 10:00 US/Pacific. One hour later, candidates were surprised to receive an email from OSI demanding that all candidates sign a Board agreement before results were posted. This was surprising because during mandatory orientation, candidates were told the opposite: that a Board agreement need not be signed until the Board formally appointed you as a Director (as the elections are only advisory &mdash: OSI's Board need not follow election results in any event. It was also surprising because the deadline was a mere 47 hours later (WED 2025-03-19 at 10:00 US/Pacific).
Many of us candidates attempted to get clarification over the last 46 hours, but OSI has not communicated clear answers in response to those requests. Based on these unclear responses, the best we can surmise is that OSI intends to modify the ballots cast by Affiliates and Members to remove any candidate who misses this new deadline. We are loathe to assume the worst, but there's little choice given the confusing responses and surprising change in requirements and deadlines.
So, I decided to sign a Board Agreement with OSI. Here is the PDF that I just submitted to the OSI. I emailed it to OSI instead. OSI did recommend DocuSign, but I refuse to use proprietary software for my FOSS volunteer work on moral and ethical grounds0 (see my two keynotes (FOSDEM 2019, FOSDEM 2020) (co-presented with Karen Sandler) on this subject for more info on that).
My running mate on the Shared Platform for OSI Reform, Richard Fontana, also signed a Board Agreement with OSI before the deadline as well.
0 Chad Whitacre has made unfair criticism of my refusal tog use Docusign as part of the (apparently ongoing?) 2025 OSI Board election political campaign. I respond to his comment here in this footnote (& further discussion is welcome using the fediverse, AGPLv3-powered comment feature of my blog). I've put it in this footnote because Chad is not actually raising an issue about this blog post's primary content, but instead attempting to reopen the debate about Item 4 in the Shared Platform for OSI Reform. My response follows:
In addition to the two keynotes mentioned above, I propose these analogies that really are apt to this situation:
- Imagine if the Board of The Nature Conservancy told Directors they would be required, if elected, to use a car service to attend Board meetings. It's easier, they argue, if everyone uses the same service and that way, we know you're on your way, and we pay a group rate anyway. Some candidates for open Board seats retort that's not environmentally sound, and insist — not even that other Board members must stop using the car service &mdash: but just that Directors who chose should be allowed to simply take public transit to the Board meeting — even though it might make them about five minutes late to the meeting. Are these Director candidates engaged in “passive-aggressive politicking”?
- Imagine if the Board of Friends of Trees made a decision that all paperwork for the organization be printed on non-recycled paper made from freshly cut tree wood pulp. That paper is easier to move around, they say — and it's easier to read what's printed because of its quality. Some candidates for open Board seats run on a platform that says Board members should be allowed to get their print-outs on 100% post-consumer recycled paper for Board meetings. These candidates don't insist that other Board members use the same paper, so, if these new Directors are seated, this will create extra work for staff because now they have to do two sets of print-outs to prep for Board meetings, and refill the machine with different paper in-between. Are these new Director candidates, when they speak up about why this position is important to them as a moral issue, a “a distracting waste of time”?
- Imagine if the Board of the APSCA made the decision that Directors must work through lunch, and the majority of the Directors vote that they'll get delivery from a restaurant that serves no vegan food whatsoever. Is it reasonable for this to be a non-negotiable requirement — such that the other Directors must work through lunch and just stay hungry? Or should they add a second restaurant option for the minority? After all, the ASPCA condemns animal cruelty but doesn't go so far as to demand that everyone also be a vegan. Would the meat-eating directors then say something like “opposing cruelty to animals could be so much more than merely being vegan” to these other Directors?
An Update Regarding the 2025 Open Source Initiative Elections
I've explained in other posts that I ran for the 2025 Open Source Initative Board of Directors in the “Affiliate” district.
Voting closed on Monday 2025-03-17 at 10:00 US/Pacific. One hour after that, I and at least three other candidates received the following email:
Date: Mon, 17 Mar 2025 11:01:22 -0700(The link email did arrived too, with a link to a proprietary service called DocuSign. Fontana downloaded the PDF out of DocuSign and it appears to match the document found here. This document includes a clause that Fontana and I explicitly indicated in our OSI Reform Platform should be rewritten. )
From: OSI Elections team <elections@opensource.org>
To: Bradley Kuhn <bkuhn@ebb.org>
Subject: TIME SENSITIVE: sign OSI board agreement
Message-ID: <civicrm_67d86372f1bb30.98322993@opensource.org>
Thanks for participating in the OSI community polls which are now closed. Your name was proposed by community members as a candidate for the OSI board of directors. Functioning of the board of directors is critically dependent on all the directors committing to collaborative practices.
For your name to be considered by the board as we compute and review the outcomes of the polls,you must sign the board agreement before Wednesday March 19, 2025 at 1700 UTC (check times in your timezone). You’ll receive another email with the link to the agreement.
TIME SENSITIVE AND IMPORTANT: this is a hard deadline.
Please return the signed agreement asap, don’t wait.
Thanks
OSI Elections team
All the (non-incumbent) candidates are surprised by this. OSI told us during the mandatory orientation meetings (on WED 2025-02-19 & again on TUE 2025-02-25) that the Board Agreement needed to be signed only by the election winners who were seated as Directors. No one mentioned (before or after the election) that all candidates, regardless of whether they won or lost, needed to sign the agreement. I've also served o many other 501(c)(3) Boards, and I've never before been asked to sign anything official for service until I was formally offered the seat.
Can someone more familiar with the OSI election process explain this? Specifically, why are all candidates (even those who lose) required to sign the Board Agreement before election results are published? Can folks who ran before confirm for us that this seems to vary from procedures in past years? Please reply on the fediverse thread if you have information. Richard Fontana also reached out to OSI on their discussion board on the same matter.