The lower-post-volume people behind the software in Debian. (List of feeds.)

There’s a new math result which is a milestone for AI mathematics. It’s a human readable and insightful result on a conjecture of some renown. It improves on a previous construction of Erdos to make a set of points in the plane with a relatively large number of unit distances between them.
Where the AI got its inspiration from can be as ineffable as it is for humans, but there’s a plausible narrative that it got direct inspiration from the Erdos construction. A proof tells a story, and the moral of the story belongs to the reader not the storyteller. To some the Erdos construction is a story about square grids. But it can also be read as a story about taking an algebraic construction, finding a projection onto geometric space which preserves unit distances, and then solving a number theory problem in the algebraic space to have lots of unit distances. Instead of using the straightforward grid structure the new construction uses a more esoteric algebraic construction, involving pulling in a powerful theorem from a completely different place. In a funny detail the underlying number theory problem it relies on is fairly trivial while the Erdos one requires some work. That is not coincidental with there being a lot more edges: the requirements for them to work are much less stringent.
The obvious question is: What does it look like? The papers and articles contain no pictures of the new construction and there’s a reason for that but another reason one should be included anyway. The construction used for small examples produces some very tesseract-looking things and at larger scales looks like a point cloud without any obvious nice geometric properties. At the smaller scale where the structure can be gleaned it looks actively counterproductive, producing fewer distance coincidences than the Erdos construction. You have to crank up the number of dimensions and the radius of the ball up quite a bit before it starts getting favored, and by then the number of points has become huge.
But that doesn’t mean there can’t be a picture! You can have a density plot where regions with more points points are darker, and having the picture may yield geometric insights which the algebraic construction was obfuscating. Does it look like the shadow of a sphere? A disc? A Gaussian plot? Whatever the shape is, the next question is: How big is the unit distance compared to the width of the shape? Here is where it gets interesting: It appears to be that the distance is quite small. For me that starts raising alarm bells. Didn’t we already crop to within a ball in the algebraic construction? Yes we did, but that was to make the number of points finite, not to reduce the geometric range. The projection between the algebraic and geometric space makes many things look very different with the one exception that certain exactly unit distances stay unit. Other distances get scrambled. So that raises the next question: Why can’t we just crop geometrically to some small constant factor of the unit distance at the end, thus making a much better result by reducing the denominator? This might actually work! It depends on just how much smaller the cropping is and how sparse of a region can be found. I honestly don’t know if it works out, and don’t have the tools to analyze this because it’s a bizarre jump back into geometric space from algebraic but it’s plausible and the benefits might be big, so it’s certainly worthy of further analysis.
The concrete bounds now stand at there being a lower bound on the polynomial exponent of 1.014, up from the previously conjectured to be optimal value of 1. The known upper bound is 4/3. That range of possibilities is very interesting and we most definitely have not heard the last word on this. The AI construction just showed 1+e and the 1.014 is a later explicit improvement. Maybe there will be a polymath project on it.
Talking to AI (specifically Opus 4.7) about this is very interesting. It can read through the whole construction no problem, and talk about it fluently. But then when it gets into discussing geometric insights its intuition is garbage. With some prodding I can get it to understand basic points, and it readily understand after they’re pointed out that these are very basic things, but it just can’t wrap its brain around anything without having it explained. It seems like the new construction is exactly the thing it happens to be super good at: Tackling something purely symbolically, pulling in outside theorems and constructions from seemingly totally unrelated areas, following a roadmap which had already been laid out for it. Drawing from geometric intuitions is something which it simply can’t do. The contrast is very bizarre in this particular case where it’s going from genius to idiot talking about the exact same problem with the perspective shifted only slightly. I haven’t, and probably won’t, grok the full new construction, but it was able to explain the basics outline of the construction to me and construct some basic examples, which was fun and interesting.
The other notable thing about the AI strength here is that this is a constructive proof. AI seems to be better at that than proofs of nonexistence, which is consistent with it being fast and not having much insight. Constructions require fiddling around until you find something, with much clearer partial results along the way, where with proofs of non-existence you have to intuit a roadmap or you don’t make any obvious headway until the very end. The proof of the Robbins conjecture is similar: The core insight is up front realizing that you can find a counterexample to Modus Tollens and then do proof by contradiction. After that it looks a lot more like finding a solution to a post substitution problem than a meaningful proof.

Approval voting is an election method voters say ‘yes’ or ‘no’ to each candidate and whoever gets the most ‘yes’ votes wins. It isn’t a popular or good idea. It’s mostly promoted by one guy, but the internet being what it is he’s managed to make the appearance that it’s a serious thing, based mostly on having gotten a real math paper published and once having convinced a very geriatric Kenneth Arrow to be interviewed who then acted like a gracious guest. I’ve now spent an unjustified amount of time arguing with this person and digging into what that paper says, so I’ll explain what’s wrong with it for your benefit.
When argued with this person does a lot of talking about ‘math’ and ‘theorem’. Those familiar with Arrow’s theorem might find this a little odd. Arrow’s theorem is a theorem. How could two theorems say contradictory things? It comes down to what assumptions you make. Assumptions may or may not correlate with the real world. Which theorem applies is an empirical question about which one’s assumptions are most accurate.
The core insight of Arrow’s theorem is this: Consider an election which there are three parties, the Alice, Bob, and Carol parties, named after their preferred candidates. They’re all close to the same size, and the Alice party’s preferred candidates are Alice, then Bob, then Carol, in that order. For the Bob party it’s Bob, Carol, Alice, and for the Carol party it’s Carol, Alice, Bob. This is a very strange and confused scenario which doesn’t happen very often in practice, but it can happen, and Arrow’s theorem basically says there’s no perfect way to handle it, although there are reasonable things which can be done in practice.1
The paper in question is spun as claiming that approval voting is a loophole around the no spoilers criterion. That criterion specifically says that if one candidate would beat another in a two-way race, then adding in a third candidate who doesn’t win shouldn’t switch it to the other candidate. Consider what happens in the difficult case described above when we’re using ranked choice ballots. Let’s say the numbers of members of the three parties are very slightly different and the tiebreak we choose happens to pick Bob. This is a problem because in a two way race Alice would beat Bob with 2/3 of the vote but now Bob wins because of Carol having been introduced even though Carol didn’t win. The same argument applies when either of the other two candidates win.
Intuitively it seems like moving off of ranked choice ballots should make gameability worse rather than better. It allows voters to express their preferences in every scenario and the vote ranking algorithm to use all of that information. It turns this is exactly what happens for approval voting: The simplicity of picking a winner masks yet even greater opportunities for voters to get what they want by voting dishonestly. Only if you assume the fallacy that by limiting what voters can express to approve/disapprove you’ve successfully forced them to limit their preferences to approve/disapprove does it hold up.
Consider the difficult case with approval voting. Let’s say the voters vote completely honestly. Or maybe they vote strategically based on some complex negotiation which happened ahead of time. Which assumption you make doesn’t matter for getting to the conclusion. One way or another, one of the candidates will win. Let’s say it’s Bob. Why won’t Alice beat Bob in a two-way race? The details are a bit involved (this was, in fact, the subject of a publishable paper) but it rests deeply on a fundamental assumption: Because the ballots are yes/no, the feelings of the voters about candidates are yes/no. In particular, it assumes that in a two way race between Alice and Bob voters who like both candidates or dislike both candidates will state so honestly, putting in a wasted ballot, instead of strategically voting yes to the candidate they like more and no to the candidate they dislike more. They’re supposed to say ‘Both candidates are great, don’t care’ or ‘Two evils, no lesser’. Any voters who do otherwise are Bad, Immoral, and defiling the mathematical beauty of the voting system. This is, to put it politely, an unrealistic assumption, and real world voting systems should not be designed based on it.
There are other arguments which could be made for and against approval voting but no-spoilers was chosen as the supposedly unassailable point in its favor so having debunked it I’m now going to declare victory rather than doing a comprehensive review of voting systems. Ranked choice remains the best option, with some tweaks like allowing voters to list candidates as tied in preference being legitimate practical improvements.2
The best algorithm in practice is to use ranked choice ballots and say that whoever would win a 2-way race against every other candidate is the winner. If there’s no single candidate who meets that criterion then you remove whichever candidate got the fewest first place votes and repeat the process. In addition to being simple and easy to explain, this minimizes gameability by minimizing the amount of information used from each ballot and maximizing the amount of deviance voters have to make from their honest preferences if they try to game the system.
There’s still some spoilage or at least judgement calls necessary. For example if there are 5 cadidates in a race and someone votes three of them in third and no votes for the others do they want those to be ahead of or behind the other two?
This post attempts to explain how Huion tablet devices currently integrate into the desktop stack. I'll touch a bit on the Huion driver and the OpenTablet driver but primarily this explains the intended integration[1]. While I have access to some Huion devices and have seen reports from others, there are likely devices that are slightly different. Huion's vendor ID is also used by other devices (UCLogic and Gaomon) so this applies to those devices as well.
This post was written without AI support, so any errors are organic artisian hand-crafted ones. Enjoy.
The graphics tablet stack
First, a short overview of the ideal graphics tablet stack in current desktops. At the bottom is the physical device which contains a significant amount of firmware. That device provides something resembling the HID protocol over the wire (or bluetooth) to the kernel. The kernel typically handles this via the generic HID drivers [2] and provides us with an /dev/input/event evdev node, ideally one for the pen (and any other tool) and one for the pad (the buttons/rings/wheels/dials on the physical tablet). libinput then interprets the data from these event nodes, passes them on to the compositor which then passes them via Wayland to the client. Here's a simplified illustration of this:

Unlike the X11 api, libinput's API works both per-tablet and per-tool basis. In other words, when you plug in a tablet you get a libinput device that has a tablet tool capability and (optionally) a tablet pad capability. But the tool will only show up once you bring it into proximity. Wacom tools have sufficient identifiers that we can a) know what tool it is and b) get a unique serial number for that particular device. This means you can, if you wanted to, track your physical tool as it is used on multiple devices. No-one [3] does this but it's possible. More interesting is that because of this you can also configure the tools individually, different pressure curves, etc. This was possible with the xf86-input-wacom driver in X but only with some extra configuration, libinput provides/requires this as the default behaviour.
The most prominent case for this is the eraser which is present on virtually all pen-like tools though some will have an eraser at the tail end and others (the numerically vast majority) will have it hardcoded on one of the buttons. Changing to eraser mode will create a new tool (the eraser) and bring it into proximity - that eraser tool is logically separate from the pen tool and can thus be configured differently. [4]
Another effect of this per-tool behaviour is also that we know exactly what a tool can do. If you use two different styli with different capabilities (e.g. one with tilt and 2 buttons, one without tilt and 3 buttons), they will have the right bits set. This requires libwacom - a library that tells us, simply: any tool with id 0x1234 has N buttons and capabilities A, B and C. libwacom is just a bunch of static text files with a C library wrapped around those. Without libwacom, we cannot know what any individual tool can do - the firmware and kernel always expose the capability set of all tools that can be used on any particular tablet. For example: wacom's devices support an airbrush tool so any tablet plugged in will announce the capabilities for an airbrush even though >99% of users will never use an airbrush [5].
The compositor then takes the libinput events, modifies them (e.g. pressure curve handling is done by the compositor) and passes them via the Wayland protocol to the client. That protocol is a pretty close mirror of the libinput API so it works mostly the same. From then on, the rest is up to the application/toolkit.
Notably, libinput is a hardware abstraction layer and conversion of hardware events into others is generally left to the compositor. IOW if you want a button to generate a key event, that's done either in the compositor or in the application/toolkit. But the current versions of libinput and the Wayland protocol do support all hardware features we're currently aware of: the various stylus types (including Wacom's lens cursor and mouse-like "puck" devices) and buttons, rings, wheels/dials, and touchstrips on pads. We even support the rather once-off Dell Canvas Totem device.
Huion devices
Huion's devices are HID compatible which means they "work" out of the box but they come in two different modes, let's call them firmware mode and tablet mode. Each tablet device pretends to be three HID devices on the wire and depending on the mode some of those devices won't send events.
Firmware mode
This is the default mode after plugging the device in. Two of the HID devices exposed look like a tablet stylus and a keyboard. The tablet stylus is usually correct (enough) to work OOTB with the generic kernel drivers, it exports the buttons, pressure, tilt, etc. The buttons and strips/wheels/dials on the tablet are configured to send key events. For example, the Inspiroy 2S I have sends b/i/e/Ctrl+S/space/Ctrl+Alt+z for the buttons and the roller wheel sends Ctrl-/Ctrl= depending on direction. The latter are often interpreted as zoom in/out so hooray, things work OOTB. Other Huion devices have similar bindings, there is quite some overlap but not all devices have exactly the same key assignments for each button. It does of course get a lot more interesting when you want a button to do something different - you need to remap the key event (ideally without messing up your key map lest you need to type an 'e' later).
The userspace part is effectively the same, so here's a simplified illustration of what happens in kernel land:

Tablet mode
If you read a special USB string descriptor from the English language ID, the device switches into tablet mode. Once in tablet mode, the HID tablet stylus and keyboard devices will stop sending events and instead all events from the device are sent via the third HID device which consists of a single vendor-specific report descriptor (read: 11 bytes of "here be magic"). Those bits represent the various features on the device, including the stylus features and all pad features as buttons/wheels/rings/strips (and not key events!). This mode is the one we want to handle the tablet properly. The kernel's hid-uclogic driver switches into tablet mode for supported devices, in userspace you can use e.g. huion-switcher. The device cannot be switched back to firmware mode but will return to firmware mode once unplugged.
Once we have the device in tablet mode, we can get true tablet data and pass it on through our intended desktop stack. Alas, like ogres there are layers.
hid-uclogic and udev-hid-bpf
Historically and thanks in large parts to the now-discontinued digimend project, the hid-uclogic kernel driver did do the switching into tablet mode, followed by report descriptor mangling (inside the kernel) so that the resulting devices can be handled by the generic HID drivers. The more modern approach we are pushing for is to use udev-hid-bpf which is quite a bit easer to develop for. But both do effectively the same thing: they overlay the vendor-specific data with a normal HID report descriptor so that the incoming data can be handled by the generic HID kernel drivers. This will look like this:

Notable here: the stylus and keyboard may still exist and get event nodes but never send events[6] but the uclogic/bpf-enabled device will be proper stylus/pad event nodes that can be handled by libinput (and thus the rest), with raw hardware data where buttons are buttons.
Challenges
Because in true manager speak we don't have problems, just challenges. And oh boy, we collect challenges as if we'd be organising the olypmics.
hid-uclogic and libinput
First and probably most embarrassing is that hid-uclogic has a different way of exposing event nodes than what libinput expects. This is largely my fault for having focused on Wacom devices and internalized their behaviour for long years. The hid-uclogic driver exports the wheels and strips on separate event nodes - libinput doesn't handle this correctly (or at all). That'd be fixable but the compositors also don't really expect this so there's a bit more work involved but the immediate effect is that those wheels/strips will likely be ignored and not work correctly. Buttons and pens work.

udev-hid-bpf and huion-switcher
hid-uclogic being a kernel driver has access to the underlying USB device. The HID-BPF hooks in the kernel currently do not, so we cannot switch the device into tablet mode from a BPF, we need it in tablet mode already. This means a userspace tool (read: huion-switcher) triggered via udev on plug-in and before the udev-hid-bpf udev rules trigger. Not a problem but it's one more moving piece that needs to be present (but boy, does this feel like the unix way...).
Huion's precious product IDs
By far the most annoying part about anything Huion is that until relatively recently (I don't have a date but maybe until 2 years ago) all of Huion's devices shared the same few USB product IDs. For most of these devices we worked around it by matching on device names but there were devices that had the same product id and device name. At some point libwacom and the kernel and huion-switcher had to implement firmware ID extraction and matching so we could differ between devices with the same 0256:006d usb IDs. Luckily this seems to be in the past now with modern devices now getting new PIDs for each individual device. But if you have an older device, expect difficulties and, worse, things to potentially break after firmware updates when/if the firmware identification string changes. udev-hid-bpf (and uclogic) rely on the firmware strings to identify the device correctly.
edit: and of course less than 24h after posting this I process a bug report about two completely different new devices sharing one of the product IDs
udev-hid-bpf and hid-uclogic
Because we have a changeover from the hid-uclogic kernel driver to the udev-hid-bpf files there are rough edges on "where does this device go". The general rule is now: if it's not a shared product ID (see above) it should go into udev-hid-bpf and not the uclogic driver. Easier to maintain, much more fire-and-forget. Devices already supported by udev-hid-bpf will remain there, we won't implement BPFs for those (older) devices, doubly so because of the aforementioned libinput difficulties with some hid-uclogic features.
Reverse engineering required
The newer tablets are always slightly different so we basically need to reverse-engineer each tablet to get it working. That's common enough for any device but we do rely on volunteers to do this. Mind you, the udev-hid-bpf approach is much simpler than doing it in the kernel, much of it is now copy-paste and I've even had quite some success to get e.g. Claude Code to spit out a 90% correct BPF on its first try. At least the advantage of our approach to change the report descriptor means once it's done it's done forever, there is no maintenance required because it's a static array of bytes that doesn't ever change.
Plumbing support into userspace
Because we're abstracting the hardware, userspace needs to be fully plumbed. This was a problem last year for example when we (slowly) got support for relative wheels into libinput, then wayland, then the compositors, then the toolkits to make it available to the applications (of which I think none so far use the wheels). Depending on how fast your distribution moves, this may mean that support is months and years off even when everything has been implemented. On the plus side these new features tend to only appear once every few years. Nonetheless, it's not hard to see why the "just sent Ctrl=, that'll do" approach is preferred by many users over "probably everything will work in 2027, I'm sure".
So, what stylus is this?
A currently unsolved problem is the lack of tool IDs on all Huion tools. We cannot know if the tool used is the two-button + eraser PW600L or the three-button-one-is-an-eraser-button PW600S or the two-button PW550 (I don't know if it's really 2 buttons or 1 button + eraser button). We always had this problem with e.g. the now quite old Wacom Bamboo devices but those pens all had the same functionality so it just didn't matter. It would matter less if the various pens would only work on the device they ship with but it's apparently quite possible to use a 3 button pen on a tablet that shipped with a 2 button pen OOTB. This is not difficult to solve (pretend to support all possible buttons on all tools) but it's frustrating because it removes a bunch of UI niceties that we've had for years - such as the pen settings only showing buttons that actually existed. Anyway, a problem currently in the "how I wish there was time" basket.
Summary
Overall, we are in an ok state but not as good as we are for Wacom devices. The lack of tool IDs is the only thing not fixable without Huion changing the hardware[7]. The delay between a new device release and driver support is really just dependent on one motivated person reverse-engineering it (our BPFs can work across kernel versions and you can literally download them from a successful CI pipeline). The hid-uclogic split should become less painful over time and the same as the devices with shared USB product IDs age into landfill and even more so if libinput gains support for the separate event nodes for wheels/strips/... (there is currently no plan and I'm somewhat questioning whether anyone really cares). But other than that our main feature gap is really the ability for much more flexible configuration of buttons/wheels/... in all compositors - having that would likely make the requirement for OpenTabletDriver and the Huion tablet disappear.
OpenTabletDriver and Huion's own driver
The final topic here: what about the existing non-kernel drivers?
Both of these are userspace HID input drivers which all use the same approach: read from a /dev/hidraw node, create a uinput device and pass events back. On the plus side this means you can do literally anything that the input subsystem supports, at the cost of a context switch for every input event. Again, a diagram on how this looks like (mostly) below userspace:

Note how the kernel's HID devices are not exercised here at all because we parse the vendor report, create our own custom (separate) uinput device(s) and then basically re-implement the HID to evdev event mapping. This allows for great flexibility (and control, hence the vendor drivers are shipped this way) because any remapping can be done before you hit uinput. I don't immediately know whether OpenTabletDriver switches to firmware mode or maps the tablet mode but architecturally it doesn't make much difference.
From a security perspective: having a userspace driver means you either need to run that driver daemon as root or (in the case of OpenTabletDriver at least) you need to allow uaccess to /dev/uinput, usually via udev rules. Once those are installed, anything can create uinput devices, which is a risk but how much is up for interpretation.
[1] As is so often the case, even the intended state does not necessarily spark joy
[2] Again, we're talking about the intended case here...
[3] fsvo "no-one"
[4] The xf86-input-wacom driver always initialises a separate eraser tool even if you never press that button
[5] For historical reasons those are also multiplexed so getting ABS_Z on a device has different meanings depending on the tool currently in proximity
[6] In our udev-hid-bpf BPFs we hide those devices so you really only get the correct event nodes, I'm not immediately sure what hid-uclogic does
[7] At which point Pandora will once again open the box because most of the stack is not yet ready for non-Wacom tool ids
Anthropic has launched Glasswing, a program to help software vendors fix all of their security problems before bad guys use them to take over the world.
For context, the state of computer security is an utter nightmare and always has been. There are massive security problems all over the place, just waiting to be discovered. Security researchers find more of them all the time, only limited by the amount of effort they put in. The only reason why the entire world hasn’t gotten hacked into oblivion long ago is that professional security researchers are, for the most part, good people trying to do good and defend rather than hack.
Anthropic’s new model seems to be a substantial advance in AI’s ability to find security problems, but this process has already started. The prior model, Opus, especially with appropriate tooling, is entirely capable of agentically searching over even a very mature codebase and finding a gigantic lump of security problems in it. This is happening for everything and has been for over a month now, which seems like forever. There’s this massive glop of security problems getting found and reported to all the big software projects, and they’re scrambling to try and fix them all at once. There’s a window of opportunity for bad guys right now to do a similar thing and find security problems in everything with very little effort, and exploit them. It’s very important that the defenders stay ahead of the game.
In the end, this will be a good thing for security. We’re going to have software with many fewer security problems in it. Even though the attackers will have enhanced capabilities of finding problems, the net balance will be fewer security problems found in the wild because there will hardly be any there to be found. But right now we have a python eating a horse situation where everybody is trying to fix everything as quickly as they possibly can after finding what would have been the next few decades’ worth of issues all in one go.
Having something like this take aim at your codebase is just going to become part of the normal development and release process. Nothing ever goes into production without a serious security scan. It's actually better than that, because it's not just going to be searching for security problems; it's going to be searching for bugs. Security problems are a particularly bad kind of bug, but it will be finding bugs in general and improving code quality overall.
Everyone assumes that AI results in very low code quality, which can happen if you use it wrong, but it can also result in very high-quality code if you use it right. It's really not clear what the net results are going to be. Likely, we're going to see some codebases with atrocious quality and some codebases with extremely high quality, and it's not going to be consistent across projects. Just like today. There are going to be some projects that are a weird combination of both, that you have very well-vetted spaghetti code.
After each release, we remove the features and options which were EOL in the previous one (we give
one release during which features can be re-enabled by the i-promise-to-fix-broken-api-user option).
We actually find a really old feature to deprecate (which predates the modern deprecation infrastructure): the addendum shows what happened, as something of an object lesson in why we have the deprecation subsystem!
Claude had a leak of their source code, and people have been having a whole lot of fun laughing at how bad it is. You might wonder how this could happen. The answer is dogfooding run amok.
Dogfooding is when you use your own product. It’s a good idea. But it can turn into a cult activity where it goes beyond any reasonable limits. In this case, the idea is vibe coding, where you make a point of literally making no contribution to what’s going on under the hood, not even looking at it.
This is, of course, ridiculous. It’s not like there isn’t human contribution happening here. For starters, you’re using a human language, and the machine is using that same human language for its own internal thought processes. You could argue that that other humans, not on the development team, did all that foundational work and your team are doing pure vibe coding. But even that isn’t what’s happening. You’re still building the infrastructure of things like plan files (That’s fancy talk for ‘todo lists’), skills, and rules. The machine works very poorly without being given a framework.
So pure vibe coding is a myth. But they’re still trying to do it, and this leads to some very ridiculous outcomes. For example, a human actually looked and saw a lot of duplication between them. Now, you might ask: why didn’t any of the developers just go look for themselves? Again, it’s vibe coding. Looking under the hood is cheating. You’re only supposed to have vague conversations with the machine about what it’s doing.
This gets particularly silly because it’s not like there’s some super technical thing under the hood that the general public couldn’t understand. This code is written in English. Anyone could read it. It’s easy enough to go through and notice, “wow, there’s a whole bunch of things that are both agents and tools. That’s kind of redundant, maybe we should clean this up.”
This happens all the time in software. Projects are born in sin. Historically a software project would usually have so much tech debt that if you were doing what made sense from a pure development standpoint you would literally do nothing but clean up mess for the entire next year. Now that you can use AI for coding, you can get that cleanup done in sometimes a matter of weeks, or get it paid down a bit slower will still writing new features. And you should. You should strive for much higher quality. Helping you clean up mess is something AI is actually very good at.
In this particular case, a human could have told the machine: “There’s a lot of things that are both agents and tools. Let’s go through and make a list of all of them, look at some examples, and I’ll tell you which should be agents and which should be tools. We’ll have a discussion and figure out the general guidelines. Then we’ll audit the entire set, figure out which category each one belongs in, port the ones that are in the wrong type, and for the ones that are both, read through both versions and consolidate them into one document with the best of both.”
The AI is actually very good at this, especially if you have a conversation with it beforehand. That’s what Ask mode is for. You walk through some examples, share your reasoning, and correct the wrong things it says when trying to sycophantically agree with you. After enough back and forth, it’s often able to do what looks like one-shotting a task. It’s not really one-shotting at all. There was a lot of back and forth with you, the human, beforehand. But when it actually goes to do the thing, it zooms ahead because you’ve already clarified the weird edge cases and the issues likely to come up.
But the Claude team isn’t doing that. They’re going completely overboard with dogfooding and utterly refusing to even spend a few minutes looking under the hood, noticing what’s broken, and explaining the mess to the machine. That wouldn’t even be a big violation of the vibe coding concept. You’re reading the innards a little but you’re only giving high-level, conceptual, abstract ideas about how problems should be solved. The machine is doing the vast majority, if not literally all, of the actual writing.
I’ve been doing this for months. I’ll start a conversation by saying “Let’s audit this codebase for unreachable code,” or “This function makes my eyes bleed,” and we’ll have a conversation about it until something actionable comes up. Then I explain what I think should be done and we’ll keep discussing it until I stop having more thoughts to give and the machine stops saying stupid things which need correcting. Then I tell it to make a plan and hit build. This is my life. The AI is very bad at spontaneously noticing, “I’ve got a lot of spaghetti code here, I should clean it up.” But if you tell it this has spaghetti code and give it some guidance (or sometimes even without guidance) it can do a good job of cleaning up the mess.
You don’t have to have poor quality software just because you’re using AI for coding. That is my hot take for today. People have bad quality software because they decide to have bad quality software. I have been screaming at my computer this past week dealing with a library that was written by overpaid meatbags with no AI help. Bad software is a decision you make. You need to own it. You should do better.
Surprisingly and happily my last post on version control got picked up by Hacker News and got a lot of views. Thanks everybody who engaged with it, and welcome new subscribers. I put a ridiculous amount of work into these things and it’s nice when there’s something to show for it.
Something I didn’t quite realize when writing that last post is that in addition to supporting ‘safe rebase’ by picking one of the parents to be the ‘primary’ one, it’s possible to support ‘safe squash’ by picking a further back ancestor to be the ‘primary’ one. The advantage of this approach is that it gives you strictly more information than the Git approach. If you make the safe versions of blame/history always follow the primary path then if you perform all the same commands in the same order with both implementations then the outputs can be made to look nearly identical, with some caveats about subtle edge cases where the safe versions are behaving more reasonably. But the safe versions will still remember the full history, which both lets you look into what actually happened and gives you a lot less footguns related to pulling in something which was already squashed or rebased. The unsafe versions of these things literally throw out history and replace it with a fiction that whoever did the final operation wrote everything, or that the original author wrote something possibly very divergent from what they actually wrote.
Git is very simple, reliable, and versatile, but it isn’t very functional. It ‘supports’ squash and rebase the way writing with a pen and paper ‘supports’ inline editing. It implicitly makes humans do a lot of the version control system’s job. It’s held on because the more sophisticated version control systems haven’t had enough new functionality to compensate for their implicit reductions in versatility and reliability. My goal is to provide the foundation of something which tells a compelling enough story to be worth switching to. I think the case is good: At the minor cost of committing to diffs at commit time you can have safer versions of squash and rebase which Just Work, plus a better version of local undo for the occasional times when you encounter that nightmare and a pretty good version of cherry-picking as a bonus.
‘Committing to diffs at commit time’ is a subtle point. From a behavioral standpoint it’s a clear win. But it does create some implementation risk. Any such implementation needs a core of functionality which is is very well tested and audited and only updated extremely conservatively. This is why I made my demo implementation as simple as possible within the constraints of eventual consistency. Other systems which claim to do this I couldn’t understand their technical docs, much less develop intuitions of how they behave. With the ‘conflicts are updates which happen too close together’ approach I can intuitively reason about the behavior.
Some people found the ‘left’ and ‘right’ monikers confusing. Those are entirely advisory and can be replaced with any info you about the branch name it came from and whether it’s local or remote, or even blame information.
The ‘anchoring’ algorithm for CRDTs has been invented multiple times by independent groups in the last few years. I find it heartening that it’s only been in the last few years because I feel I should have come up with it over twenty years ago. Oddly they don’t seem to have figured out the generation counting trick, which is something I did come up with over twenty years ago. Combining the two ideas is what allows for there to be no reference to commit ids in the history and have the entire algorithm be structural.
One implementation detail I didn’t get into is that in my demo implementation it doesn’t flag ‘conflict’ sections which only consist of deletions with no insertions on either side. I’ve discussed the semantics of this with people and it seems more often than not people view flagging those as excessively conservative and are okay with them clean merging to everything gone. This is no doubt something people can get into religious wars over and it would be very interesting for someone to collect actual data about it but in practice it will inevitably be a flag individual users can set to their liking and the argument is really about the default.
One interesting question about version control is whether it can ever merge together two branches which look the same into a version which looks like neither parent. The approach I’ve proposed avoids doing that in a lot of practical cases which blow up in your face pretty badly, but that doesn’t mean it never does it. For example if you start out with XaXbX and one branch goes XaXbX → aXbX → XX while the other branch goes XaXbX → XaXb → XX. Then when you merge them together the first branch has deleted the first X of three while the second branch has deleted the last X of three so they’ll clean merge into a single X. This is a fairly artificial example which it would be hard to have happen in practice even if X is a blank line, especially if you use a diff algorithm which tries hard to keep the place repeated lines get attached to be reliable and consistent. But if it were to happen it feels like the history has ‘earned’ this funny behavior and going down to a single X with no conflict really is the right thing to do, as counterintuitive as that may be before you’ve worked through this example.
There was some discussion about my comment at the bottom of the last post about the code being artisanal but the post not. The risk with AI is that the code is a spaghetti mess which nobody realizes because no human has ever read it. There’s clear benefit to artisanal coding, or at least human auditing. The risks of AI assisted writing are a lot less. Humans understand what the words say. The AI’s writing is a lot breezier but less interesting but for reference materials that’s probably what you want. I did repeatedly go through that entire last post and tell the AI things which were wrong and should be changed. The experience was much better than manually editing because the AI could include whatever I said more quickly, in a more appropriate location, and with better wordsmithing than if I’d done it by hand. I didn’t try to change the tone to not sound like AI because that would have been more work and because I think it’s funny to encourage AI doomsaying by making it look like AI can write posts like that. This post was written entirely artisanally. Hopefully the term ‘artisanal code’ becomes a thing.
I’m releasing Manyana, a project which I believe presents a coherent vision for the future of version control — and a compelling case for building it.
It’s based on the fundamentally sound approach of using CRDTs for version control, which is long overdue but hasn’t happened yet because of subtle UX issues. A CRDT merge always succeeds by definition, so there are no conflicts in the traditional sense — the key insight is that changes should be flagged as conflicting when they touch each other, giving you informative conflict presentation on top of a system which never actually fails. This project works that out.
Better conflict presentation
One immediate benefit is much more informative conflict markers. Two people branch from a file containing a function. One deletes the function. The other adds a line in the middle of it. A traditional VCS gives you this:
<<<<<<< left
=======
def calculate(x):
a = x * 2
logger.debug(f"a={a}")
b = a + 1
return b
>>>>>>> rightTwo opaque blobs. You have to mentally reconstruct what actually happened.
Manyana gives you this:
<<<<<<< begin deleted left
def calculate(x):
a = x * 2
======= begin added right
logger.debug(f"a={a}")
======= begin deleted left
b = a + 1
return b
>>>>>>> end conflictEach section tells you what happened and who did it. Left deleted the function. Right added a line in the middle. You can see the structure of the conflict instead of staring at two blobs trying to figure it out.
What CRDTs give you
CRDTs (Conflict-Free Replicated Data Types) give you eventual consistency: merges never fail, and the result is always the same no matter what order branches are merged in — including many branches mashed together by multiple people working independently. That one property turns out to have profound implications for every aspect of version control design.
Line ordering becomes permanent. When two branches insert code at the same point, the CRDT picks an ordering and it sticks. This prevents problems when conflicting sections are both kept but resolved in different orders on different branches.
Conflicts are informative, not blocking. The merge always produces a result. Conflicts are surfaced for review when concurrent edits happen “too near” each other, but they never block the merge itself. And because the algorithm tracks what each side did rather than just showing the two outcomes, the conflict presentation is genuinely useful.
History lives in the structure. The state is a weave — a single structure containing every line which has ever existed in the file, with metadata about when it was added and removed. This means merges don’t need to find a common ancestor or traverse the DAG. Two states go in, one state comes out, and it’s always correct.
Rebase without the nightmare
One idea I’m particularly excited about: rebase doesn’t have to destroy history. Conventional rebase creates a fictional history where your commits happened on top of the latest main. In a CRDT system, you can get the same effect — replaying commits one at a time onto a new base — while keeping the full history. The only addition needed is a “primary ancestor” annotation in the DAG.
This matters because aggressive rebasing quickly produces merge topologies with no single common ancestor, which is exactly where traditional 3-way merge falls apart. CRDTs don’t care — the history is in the weave, not reconstructed from the DAG.
What this is and isn’t
Manyana is a demo, not a full-blown version control system. It’s about 470 lines of Python which operate on individual files. Cherry-picking and local undo aren’t implemented yet, though the README lays out a vision for how those can be done well.
What it is is a proof that CRDT-based version control can handle the hard UX problems and come out with better answers than the tools we’re all using today — and a coherent design for building the real thing.
The code is public domain. The full design document is in the README.
We’ve all heard of those network effect laws: the value of a network goes up with the square of the number of members. Or the cost of communication goes up with the square of the number of members, or maybe it was n log n, or something like that, depending how you arrange the members. Anyway doubling a team doesn't double its speed; there’s coordination overhead. Exactly how much overhead depends on how badly you botch the org design.
But there’s one rule of thumb that someone showed me decades ago, that has stuck with me ever since, because of how annoyingly true it is. The rule is annoying because it doesn’t seem like it should be true. There’s no theoretical basis for this claim that I’ve ever heard. And yet, every time I look for it, there it is.
Here we go:
Every layer of approval makes a process 10x slower
I know what you're thinking. Come on, 10x? That’s a lot. It’s unfathomable. Surely we’re exaggerating.
Nope.
Just to be clear, we're counting “wall clock time” here rather than effort. Almost all the extra time is spent sitting and waiting.
Look:
-
Code a simple bug fix
30 minutes -
Get it code reviewed by the peer next to you
300 minutes → 5 hours → half a day -
Get a design doc approved by your architects team first
50 hours → about a week -
Get it on some other team’s calendar to do all that
(for example, if a customer requests a feature)
500 hours → 12 weeks → one fiscal quarter
I wish I could tell you that the next step up — 10 quarters or about 2.5 years — was too crazy to contemplate, but no. That’s the life of an executive sitting above a medium-sized team; I bump into it all the time even at a relatively small company like Tailscale if I want to change product direction. (And execs sitting above large teams can’t actually do work of their own at all. That's another story.)
AI can’t fix this
First of all, this isn’t a post about AI, because AI’s direct impact on this problem is minimal. Okay, so Claude can code it in 3 minutes instead of 30? That’s super, Claude, great work.
Now you either get to spend 27 minutes reviewing the code yourself in a back-and-forth loop with the AI (this is actually kinda fun); or you save 27 minutes and submit unverified code to the code reviewer, who will still take 5 hours like before, but who will now be mad that you’re making them read the slop that you were too lazy to read yourself. Little of value was gained.
Now now, you say, that’s not the value of agentic coding. You don’t use an agent on a 30-minute fix. You use it on a monstrosity week-long project that you and Claude can now do in a couple of hours! Now we’re talking. Except no, because the monstrosity is so big that your reviewer will be extra mad that you didn’t read it yourself, and it’s too big to review in one chunk so you have to slice it into new bite-sized chunks, each with a 5-hour review cycle. And there’s no design doc so there’s no intentional architecture, so eventually someone’s going to push back on that and here we go with the design doc review meeting, and now your monstrosity week-long project that you did in two hours is... oh. A week, again.
I guess I could have called this post Systems Design 4 (or 5, or whatever I’m up to now, who knows, I’m writing this on a plane with no wifi) because yeah, you guessed it. It's Systems Design time again.
The only way to sustainably go faster is fewer reviews
It’s funny, everyone has been predicting the Singularity for decades now. The premise is we build systems that are so smart that they themselves can build the next system that is even smarter, that builds the next smarter one, and so on, and once we get that started, if they keep getting smarter faster enough, then the incremental time (t) to achieve a unit (u) of improvement goes to zero, so (u/t) goes to infinity and foom.
Anyway, I have never believed in this theory for the simple reason we outlined above: the majority of time needed to get anything done is not actually the time doing it. It’s wall clock time. Waiting. Latency.
And you can’t overcome latency with brute force.
I know you want to. I know many of you now work at companies where the business model kinda depends on doing exactly that.
Sorry.
But you can’t just not review things!
Ah, well, no, actually yeah. You really can’t.
There are now many people who have seen the symptom: the start of the pipeline (AI generated code) is so much faster, but all the subsequent stages (reviews) are too slow! And so they intuit the obvious solution: stop reviewing then!
The result might be slop, but if the slop is 100x cheaper, then it only needs to deliver 1% of the value per unit and it's still a fair trade. And if your value per unit is even a mere 2% of what it used to be, you’ve doubled your returns! Amazing.
There are some pretty dumb assumptions underlying that theory; you can imagine them for yourself. Suffice it to say that this produces what I will call the AI Developer’s Descent Into Madness:
-
Whoa, I produced this prototype so fast! I have super powers!
-
This prototype is getting buggy. I’ll tell the AI to fix the bugs.
-
Hmm, every change now causes as many new bugs as it fixes.
-
Aha! But if I have an AI agent also review the code, it can find its own bugs!
-
Wait, why am I personally passing data back and forth between agents
-
I need an agent framework
-
I can have my agent write an agent framework!
-
Return to step 1
It’s actually alarming how many friends and respected peers I’ve lost to this cycle already. Claude Code only got good maybe a few months ago, so this only recenlty started happening, so I assume they will emerge from the spiral eventually. I mean, I hope they will. We have no way of knowing.
Why we review
Anyway we know our symptom: the pipeline gets jammed up because of too much new code spewed into it at step 1. But what's the root cause of the clog? Why doesn’t the pipeline go faster?
I said above that this isn’t an article about AI. Clearly I’m failing at that so far, but let’s bring it back to humans. It goes back to the annoyingly true observation I started with: every layer of review is 10x slower. As a society, we know this. Maybe you haven't seen it before now. But trust me: people who do org design for a living know that layers are expensive... and they still do it.
As companies grow, they all end up with more and more layers of collaboration, review, and management. Why? Because otherwise mistakes get made, and mistakes are increasingly expensive at scale. The average value added by a new feature eventually becomes lower than the average value lost through the new bugs it causes. So, lacking a way to make features produce more value (wouldn't that be nice!), we try to at least reduce the damage.
The more checks and controls we put in place, the slower we go, but the more monotonically the quality increases. And isn’t that the basis of continuous improvement?
Well, sort of. Monotonically increasing quality is on the right track. But “more checks and controls” went off the rails. That’s only one way to improve quality, and it's a fraught one.
“Quality Assurance” reduces quality
I wrote a few years ago about W. E. Deming and the "new" philosophy around quality that he popularized in Japanese auto manufacturing. (Eventually U.S. auto manufacturers more or less got the idea. So far the software industry hasn’t.)
One of the effects he highlighted was the problem of a “QA” pass in a factory: build widgets, have an inspection/QA phase, reject widgets that fail QA. Of course, your inspectors probably miss some of the failures, so when in doubt, add a second QA phase after the first to catch the remaining ones, and so on.
In a simplistic mathematical model this seems to make sense. (For example, if every QA pass catches 90% of defects, then after two QA passes you’ve reduced the number of defects by 100x. How awesome is that?)
But in the reality of agentic humans, it’s not so simple. First of all, the incentives get weird. The second QA team basically serves to evaluate how well the first QA team is doing; if the first QA team keeps missing defects, fire them. Now, that second QA team has little incentive to produce that outcome for their friends. So maybe they don’t look too hard; after all, the first QA team missed the defect, it’s not unreasonable that we might miss it too.
Furthermore, the first QA team knows there is a second QA team to catch any defects; if I don’t work too hard today, surely the second team will pick up the slack. That's why they're there!
Also, the team making the widgets in the first place doesn’t check their work too carefully; that’s what the QA team is for! Why would I slow down the production of every widget by being careful, at a cost of say 20% more time, when there are only 10 defects in 100 and I can just eliminate them at the next step for only a 10% waste overhead? It only makes sense. Plus they'll fire me if I go 20% slower.
To say nothing of a whole engineering redesign to improve quality, that would be super expensive and we could be designing all new widgets instead.
Sound like any engineering departments you know?
Well, this isn’t the right time to rehash Deming, but suffice it to say, he was on to something. And his techniques worked. You get things like the famous Toyota Production System where they eliminated the QA phase entirely, but gave everybody an “oh crap, stop the line, I found a defect!” button.
Famously, US auto manufacturers tried to adopt the same system by installing the same “stop the line” buttons. Of course, nobody pushed those buttons. They were afraid of getting fired.
Trust
The basis of the Japanese system that worked, and the missing part of the American system that didn’t, is trust. Trust among individuals that your boss Really Truly Actually wants to know about every defect, and wants you to stop the line when you find one. Trust among managers that executives were serious about quality. Trust among executives that individuals, given a system that can work and has the right incentives, will produce quality work and spot their own defects, and push the stop button when they need to push it.
But, one more thing: trust that the system actually does work. So first you need a system that will work.
Fallibility
AI coders are fallible; they write bad code, often. In this way, they are just like human programmers.
Deming’s approach to manufacturing didn’t have any magic bullets. Alas, you can’t just follow his ten-step process and immediately get higher quality engineering. The secret is, you have to get your engineers to engineer higher quality into the whole system, from top to bottom, repeatedly. Continuously.
Every time something goes wrong, you have to ask, “How did this happen?” and then do a whole post-mortem and the Five Whys (or however many Whys are in fashion nowadays) and fix the underlying Root Causes so that it doesn’t happen again. “The coder did it wrong” is never a root cause, only a symptom. Why was it possible for the coder to get it wrong?
The job of a code reviewer isn't to review code. It's to figure out how to obsolete their code review comment, that whole class of comment, in all future cases, until you don't need their reviews at all anymore.
(Think of the people who first created "go fmt" and how many stupid code review comments about whitespace are gone forever. Now that's engineering.)
By the time your review catches a mistake, the mistake has already been made. The root cause happened already. You're too late.
Modularity
I wish I could tell you I had all the answers. Actually I don’t have much. If I did, I’d be first in line for the Singularity because it sounds kind of awesome.
I think we’re going to be stuck with these systems pipeline problems for a long time. Review pipelines — layers of QA — don’t work. Instead, they make you slower while hiding root causes. Hiding causes makes them harder to fix.
But, the call of AI coding is strong. That first, fast step in the pipeline is so fast! It really does feel like having super powers. I want more super powers. What are we going to do about it?
Maybe we finally have a compelling enough excuse to fix the 20 years of problems hidden by code review culture, and replace it with a real culture of quality.
I think the optimists have half of the right idea. Reducing review stages, even to an uncomfortable degree, is going to be needed. But you can’t just reduce review stages without something to replace them. That way lies the Ford Pinto or any recent Boeing aircraft.
The complete package, the table flip, was what Deming brought to manufacturing. You can’t half-adopt a “total quality” system. You need to eliminate the reviews and obsolete them, in one step.
How? You can fully adopt the new system, in small bites. What if some components of your system can be built the new way? Imagine an old-school U.S. auto manufacturer buying parts from Japanese suppliers; wow, these parts are so well made! Now I can start removing QA steps elsewhere because I can just assume the parts are going to work, and my job of "assemble a bigger widget from the parts" has a ton of its complexity removed.
I like this view. I’ve always liked small beautiful things, that’s my own bias. But, you can assemble big beautiful things from small beautiful things.
It’s a lot easier to build those individual beautiful things in small teams that trust each other, that know what quality looks like to them. They deliver their things to customer teams who can clearly explain what quality looks like to them. And on we go. Quality starts bottom-up, and spreads.
I think small startups are going to do really well in this new world, probably better than ever. Startups already have fewer layers of review just because they have fewer people. Some startups will figure out how to produce high quality components quickly; others won't and will fail. Quality by natural selection?
Bigger companies are gonna have a harder time, because their slow review systems are baked in, and deleting them would cause complete chaos.
But, it’s not just about company size. I think engineering teams at any company can get smaller, and have better defined interfaces between them.
Maybe you could have multiple teams inside a company competing to deliver the same component. Each one is just a few people and a few coding bots. Try it 100 ways and see who comes up with the best one. Again, quality by evolution. Code is cheap but good ideas are not. But now you can try out new ideas faster than ever.
Maybe we’ll see a new optimal point on the monoliths-microservices continuum. Microservices got a bad name because they were too micro; in the original terminology, a “micro” service was exactly the right size for a “two pizza team” to build and operate on their own. With AI, maybe it's one pizza and some tokens.
What’s fun is you can also use this new, faster coding to experiment with different module boundaries faster. Features are still hard for lots of reasons, but refactoring and automated integration testing are things the AIs excel at. Try splitting out a module you were afraid to split out before. Maybe it'll add some lines of code. But suddenly lines of code are cheap, compared to the coordination overhead of a bigger team maintaining both parts.
Every team has some monoliths that are a little too big, and too many layers of reviews. Maybe we won't get all the way to Singularity. But, we can engineer a much better world. Our problems are solvable.
It just takes trust.
Since nobody reads to the end of my posts I’ll start this one with the actionable experiment:
Deep neural network have a fundamental problem. The thing which makes them able to be trained also makes them susceptible to Manchurian Candidate type attacks where you say the right gibberish to them and it hijacks their brain to do whatever you want. They’re so deeply susceptible to this that it’s a miracle they do anything useful at all, but they clearly do and mostly people just pretend this problem is academic when using them in the wild even though the attacks actually work.
There’s a loophole to this which it might be possible to make reliable: thinking. If an LLM spends time talking to itself then it might be possible for it to react to a Manchurian Candidate attack by initially being hijacked but then going ‘Wait, what am I talking about?’ and pulling itself together before giving its final answer. This is a loophole because the final answer changes chaotically with early word selection so it can’t be back propagated over.
This is something which should explicitly be trained for. During training you can even cheat and directly inject adversarial state without finding a specific adversarial prompt which causes that state. You then get its immediate and post-thinking answers to multiple choice questions and use reinforcement learning to improve its accuracy. Make sure to also train on things where it gets the right answer immediately so you aren’t just training to always change its answer. LLMs are sneaky.
Now on to rambling thoughts.
Some people nitpicked that in my last post I was a little too aggressive not including normalization between layers and residuals, which is fair enough, they are important and possibly necessary details which I elided (although I did mention softmax), but they most definitely play strictly within the rules and the framework given, which was the bigger point. It’s still a circuit you can back propagate over. There’s a problem with online discourse in general, where people act like they’ve debunked an entire thesis if any nitpick can be found, even if it isn’t central to the thesis or the nitpick is over a word fumbling or simplification or the adjustment doesn’t change the accuracy of the thesis at all.
It’s beautifully intuitive how the details of standard LLM circuits fit together: Residuals stop gradient decay. Softmax stops gradient explosion. Transformers cause diffusion. Activation functions add in nonlinearity. There’s another big benefit of residuals which I find important but most people don’t worry about: If you just did a matrix multiplication then all permutations of the outputs would be isomorphic and have valid encodings effectively throwing away log(N!) bits from the weights which is a nontrivial loss. Residuals give an order and make the permutations not at all isomorphic. One quirk of the vernacular is that there isn’t a common term for the reciprocal of the gradient, the size of training adjustments, which is the actual problem. When you have gradient decay you have adjustment explosion and the first layer weights become chaotic noise. When you have gradient explosion you have adjustment decay and the first layer weights are frozen and unchanging. Both are bad for different reasons.
There are clear tradeoffs between fundamental limitations and practical trainability. Simple DNNs get mass quantities of feedback but have slightly mysterious limitations which are terrifying. Thinking has slightly less limitations at the cost of doing the thinking both during running and training where it only gets one unit of feedback per entire session instead of per word. Genetic algorithms have no limitations on the kinds of functions then can handle at all at the cost of being utterly incapable of utilizing back propagation. Simple mutational hill climbing has essentially no benefit over genetic algorithms.
On the subject of activation functions, sometimes now people use Relu^2 which seems directly against the rules and only works by ‘divine benevolence’. There must be a lot of devil in the details in that its non-scale-freeness is leveraged and everything is normed to make the values mostly not go above 1 so there isn’t too much gradient growth. I still maintain trying Reluss is an experiment worth doing.
Some things about the structure of LLMs are bugging me (This is a lot fuzzier and more speculative than the above). In the later layers the residuals make sense but for the first few they’re forcing it to hold onto input information in its brain while it’s trying to form more abstract thoughts so it’s going to have to arbitrarily pick some bits to sacrifice. Of course the actual inputs to an LLM have special handling so this may not matter, at least not for the main part of everything. But that raises some other points which feel off. The input handling being special is a bit weird, but maybe reasonable. It still has the property that in practice the input is completely jamming the first layer for a simply practical reason: The ‘context window’ is basically the size of its brain, and you don’t have to literally overwhelm the whole first layer with it, but if you don’t you’re missing out on potentially useful content, so in practice people overwhelm its brain and figure the training will make it make reasonable tradeoffs on which tokens it starts ignoring, although I suspect in practice it somewhat arbitrarily picks token offsets to just ignore so it has some brain space to think. It also feels extremely weird that it has special weights for all token offset. While the very last word is special and the one before that less so, that goes down quickly and it seems wrong that the weights related the hundredth to hundred and first token back are unrelated to the weights related to the hundred and first and hundred and second token back. Those should be tied together so it’s getting trained as one thing. I suspect that some of that is redundant and inefficient and some of it it is again ignoring parts of the input so it has brain space to think.
In 1995 someone could have written a paper which went like this (using modern vernacular) and advanced the field of AI by decades:
The central problem with building neural networks is training them when they’re deeper than two layers due to gradient descent and gradient decay. You can get around this problem by building a neural network which has N values at each layer which are then multiplied by an NxN matrix of weights and have Relu applied to them afterwards. This causes the derivative of effects on the last layer to be proportionate with the effects on the first layer no matter how deep the neural network is. This represents a quirky family of functions whose theoretical limitations are mysterious but demonstrably work well for simple problems in practice. As computers get faster it will be necessary to use a sub-quadratic structures for the layers.
History being the quirky thing that it is what actually happened is decades later the seminal paper on those sub-quadratic structures happened to stumble across making everything sublinear and as a result people are confused as to which is actually the core insight. But the structure holds: In a deep neural network, you stick to relu, softmax, sigmoid, sin, and other sublinear functions and magically can train neural networks no matter how deep they are.
There are two big advantages which digital brains have over ours: First, they can be copied perfectly for free, and second, as long as they haven’t diverged too much the results of training them can be copied from one to another. Instead of a million individuals with 20 years experience you get a million copies of one individual with 20 million years of experience. The amount of training data current we humans need to become useful is miniscule compared to current AI but they have the advantage of sheer scale.
As described previously, the Linux kernel security team does not identify or mark or announce any sort of security fixes that are made to the Linux kernel tree. So how, if the Linux kernel were to become a CVE Numbering Authority (CNA) and responsible for issuing CVEs, would the identification of security fixes happen in a way that can be done by a volunteer staff? This post goes into the process of how kernel fixes are currently automatically assigned to CVEs, and also the other “out of band” ways a CVE can be issued for the Linux kernel project.
When playing melodies the effects of microtonality are a bit disappointing. Tunes are still recognizable when played ‘wrong’. The effects are much more dramatic when you play chords:
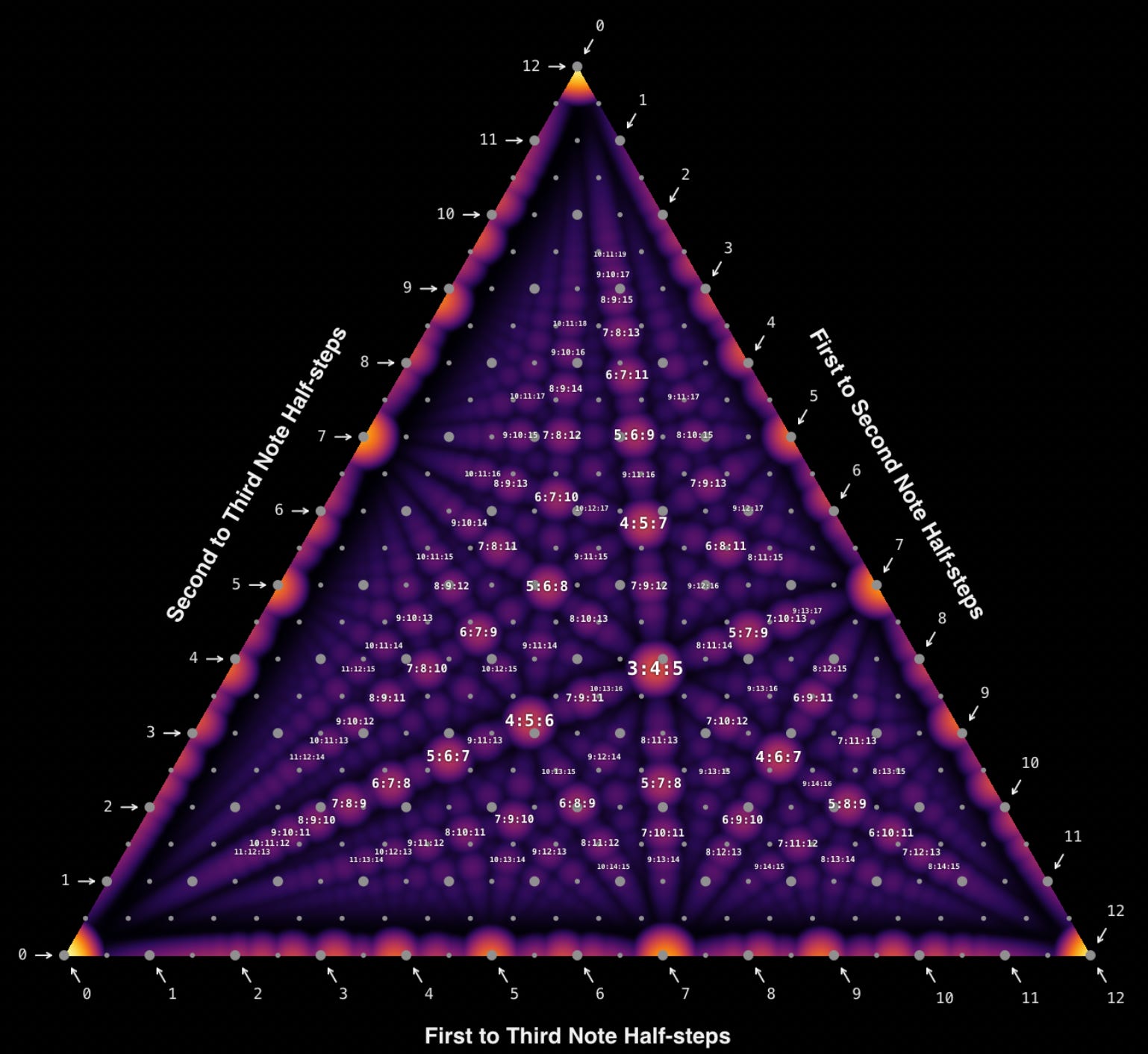
You can and should play with an interactive version of this here. It’s based off this and this with labels added by me. The larger gray dots are standard 12EDO (Equal Divisions of the Octave) positions and the smaller dots are 24EDO. There are a lot of benefits of going with 24EDO for microtonality. It builds on 12EDO as a foundation, in the places where it deviates it’s as microtonal as is possible, and it hits a lot of good chords.
Unrelated to that I’d like to report on an experiment of mine which failed. I had this idea that you could balance the volumes of dissonant notes to make dyads consonant in unusual places. It turns out this fails because the second derivative of dissonance curves is negative everywhere except unity. This can’t possibly be a coincidence. If you were to freehand something which looks like dissonance curves it wouldn’t have this property. Apparently the human ear uses positions where the second derivative of dissonance is positive to figure out what points form the components of a sound and looks for patterns in those to find complete sounds.

Here’s the story of a legendary poker hand:
Our hero decides to play with 72, which is the worst hand in Holdem and theory says he was supposed to have folded but he played it anyway.
Later he bluffed all-in with 7332 on the board and the villain was thinking about whether to call. At this point our hero offered a side bet: For a fee you can look at one of my hole cards of your choice. The villain paid the fee and happened to see the 2, at which point he incorrectly deduced that the hero must have 22 as his hole cards and folded.
What’s going on here is that the villain had a mental model which doesn’t include side bets. It may have been theoretically wrong to play 72, but in a world where side bets are allowed and the opponent’s mental model doesn’t include them it can be profitable. The reveal of information in this case was adversarial. The fee charged for it was misdirection to make the opponent think that it was a tradeoff for value rather than information which the hero wanted to give away.
What the villain should have done was think through this one level deeper. Why is my opponent offering this at all? Under what situations would they come up with it? Even without working through the details there’s a much simpler heuristic for cutting through everything: There’s a general poker tell that if you’re considering what to do and your opponent starts talking about the hand that suggests that they want you to fold. A good rule of thumb is that if you’re thinking and the opponent offers some cockamamie scheme you should just call. That certainly would have worked in this case. This seems like a rule which applies in general in life, not just in Poker.
Lots of the CVE world seems to focus on “security bugs” but I’ve found that it is not all that well known exactly how the Linux kernel security process works. I gave a talk about this back in 2023 and at other conferences since then, attempting to explain how it works, but I also thought it would be good to explain this all in writing as it is required to know this when trying to understand how the Linux kernel CNA issues CVEs.
I posted the following on my Fediverse (via Mastodon) account. I'm reposting the whole seven posts here as written there, but I hope folks will take a look at that thread as folks are engaging in conversation over there that might be worth reading if what I have to say interests you. (The remainder of the post is the same that can be found in the Fediverse posts linked throughout.)
I suppose Fediverse isn't the place people are discussing Rob Reiner. But after 36 hours of deliberating whether to say anything, I feel compelled. This thread will be long,but I start w/ most important part:
It's an “open secret” in the FOSS community that in March 2017 my brother murdered our mother. About 3k ppl/year in USA have this experience, so it's a statistical reality that someone else in FOSS experienced similar. If so, you're welcome in my PMs to discuss if you need support… (1/7)
… Traumatic loss due to murder is different than losing your grandparent/parent of age-related ailments (& is even different than losing a young person to a disease like cancer). The “a fellow family member did it” brings permanent surrealism to your daily life. Nothing good in your life that comes later is ever all that good. I know from direct experience this is what Rob Reiner's family now faces. It's chaos; it divides families forever: dysfunctional family takes on a new “expert” level… (2/7)
…as one example: my family was immediately divided about punishment. Some of my mother's relatives wanted prosecution to seek death penalty. I knew that my brother was mentally ill enough that jail or prison *would* get him killed in a prison dispute eventually,so I met clandestinely w/my brother's public defender (during funeral planning!) to get him moved to a criminal mental health facility instead of a regular prison. If they read this, it'll first time my family will find out I did that…(3/7)
…Trump's political rise (for me) links up: 5 weeks into Trump's 1ˢᵗ term, my brother murdered my mother. My (then 33yr-old) brother was severely mentally ill from birth — yet escalated to murder only then. IMO, it wasn't coincidence. My brother left voicemail approximately 5 hours before the murder stating his intent to murder & described an elaborate political delusion as the impetus. ∃ unintended & dangerous consequences of inflammatory political rhetoric on the mental ill!…(4/7)
…I'm compelled to speak publicly — for first time ≈10 yrs after the murder — precisely b/c of Trump's response.
Trump endorsed the idea that those who oppose him encourage their own murder from the mentally ill. Indeed, he said that those who oppose him are *themselves causing* mental illnesses in those around them, & that his political opponents should *expect* violence from their family members (who were apparently driven to mental illness from your opposition to Trump!)… (5/7)
…Trump's actual words:
(6/7)Rob Reiner, tortured & struggling,but once…talented movie director & comedy star, has passed away, together w/ his wife…due to the anger he caused others through his massive, unyielding, & incurable affliction w/ a mind crippling disease known as TRUMP DERANGEMENT SYNDROME…He was known to have driven people CRAZY by his raging obsession of…Trump, w/ his obvious paranoia reaching new heights as [my] Administration surpassed all goals and expectations of greatness…
My family became ultra-pro-Trump after my mom's murder. My mom hated politics: she was annoyed *both* if I touted my social democratic politics & if my dad & his family stated their crypto-fascist views. Every death leaves a hole in a community's political fabric. 9+ years out, I'm ostracized from my family b/c I'm anti-Trump. Trump stated perhaps what my family felt but didn't say: those who don't support Trump are at fault when those who fail to support Trump are murdered. (7/7)
[ Finally, I want to also quote this one reply I also posted in the same thread: I ask everyone, now that I've stated this public, that I *know* you're going to want to search the Internet for it, & you will find a lot. Please, please, keep in mind that the Police Department & others basically lied to the public about some of the facts of the case. I seriously considered suing them for it, but ultimately it wasn't worth my time. But, please everyone ask me if you are curious about any of the truth of the details of the crime & its aftermath …
With all of the different Linux kernel stable releases happening (at least 1 stable branch and multiple longterm branches are active at any one point in time), keeping track of what commits are already applied to what branch, and what branch specific fixes should be applied to, can quickly get to be a very complex task if you attempt to do this manually. So I’ve created some tools to help make my life easier when doing the stable kernel maintenance work, which ended up making the work of tracking CVEs much simpler to manage in an automated way.