The lower-post-volume people behind the software in Debian. (List of feeds.)
Happy July 4th! For those of us around the world contemplating independence, it's a good day to think about how we came to rely on expensive cloud infrastructure for our fundamental computing needs.
With that in mind, here is my latest toy project: an open source tool that makes replicating, forking, sharing, and running container snapshots fast and easy across cloud and personal devices.
It's fun to play with, especially on bare metal hardware you run at home, or rent from a provider like Hetzner or OVH. Or, because it uses Tailscale, why not all of them in a single mesh?
There's a lot more to say but I don't have time right now. Details are in the README.
I will say this: humans and AI agents both want the same things when they're trying to get work done. Ephemeral containers aren't really it. But how about unlimited disk space, fast CPUs, an undo button, and the ability to move to whatever provider offers the best hardware at the best price? That's more like it.
Go visit thundersnap on github and tell me what you think!
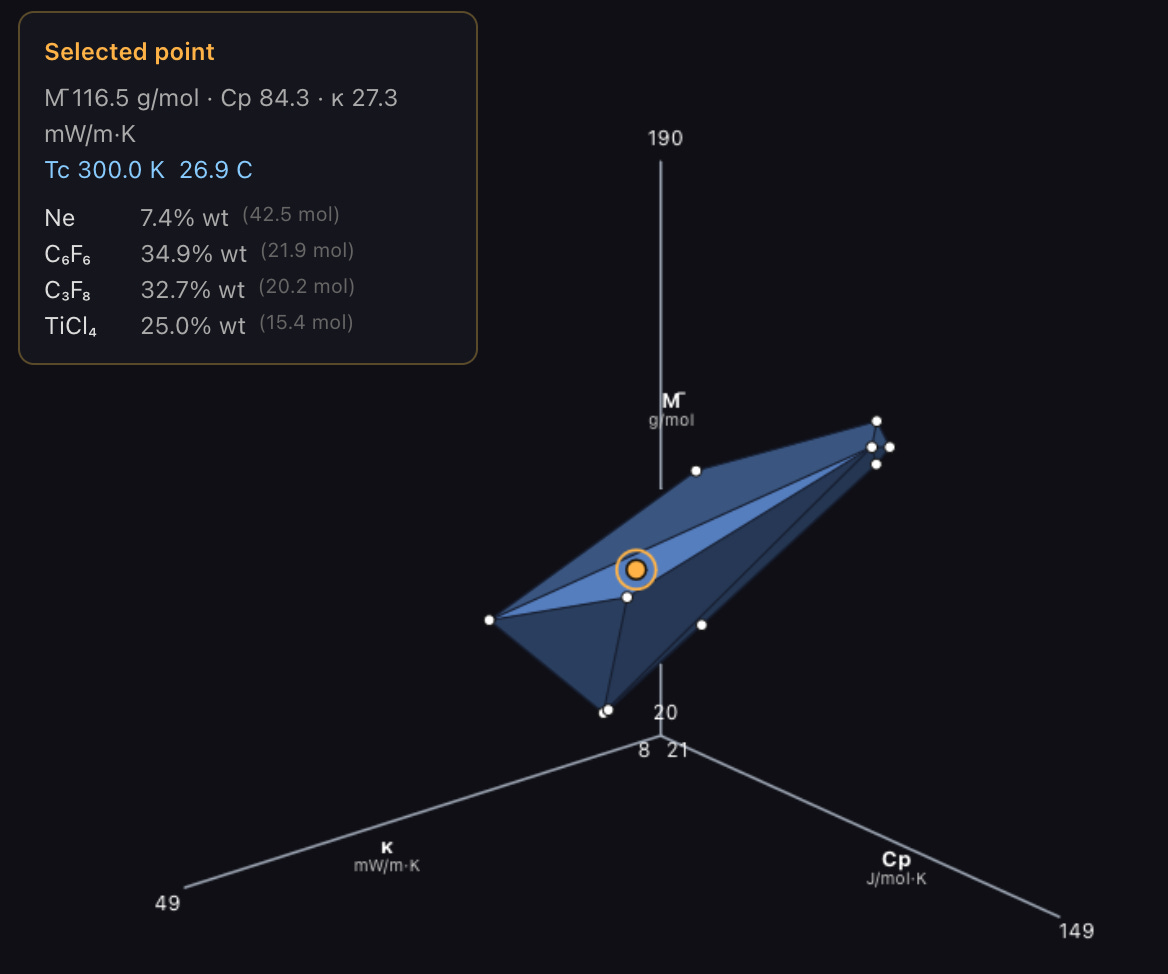
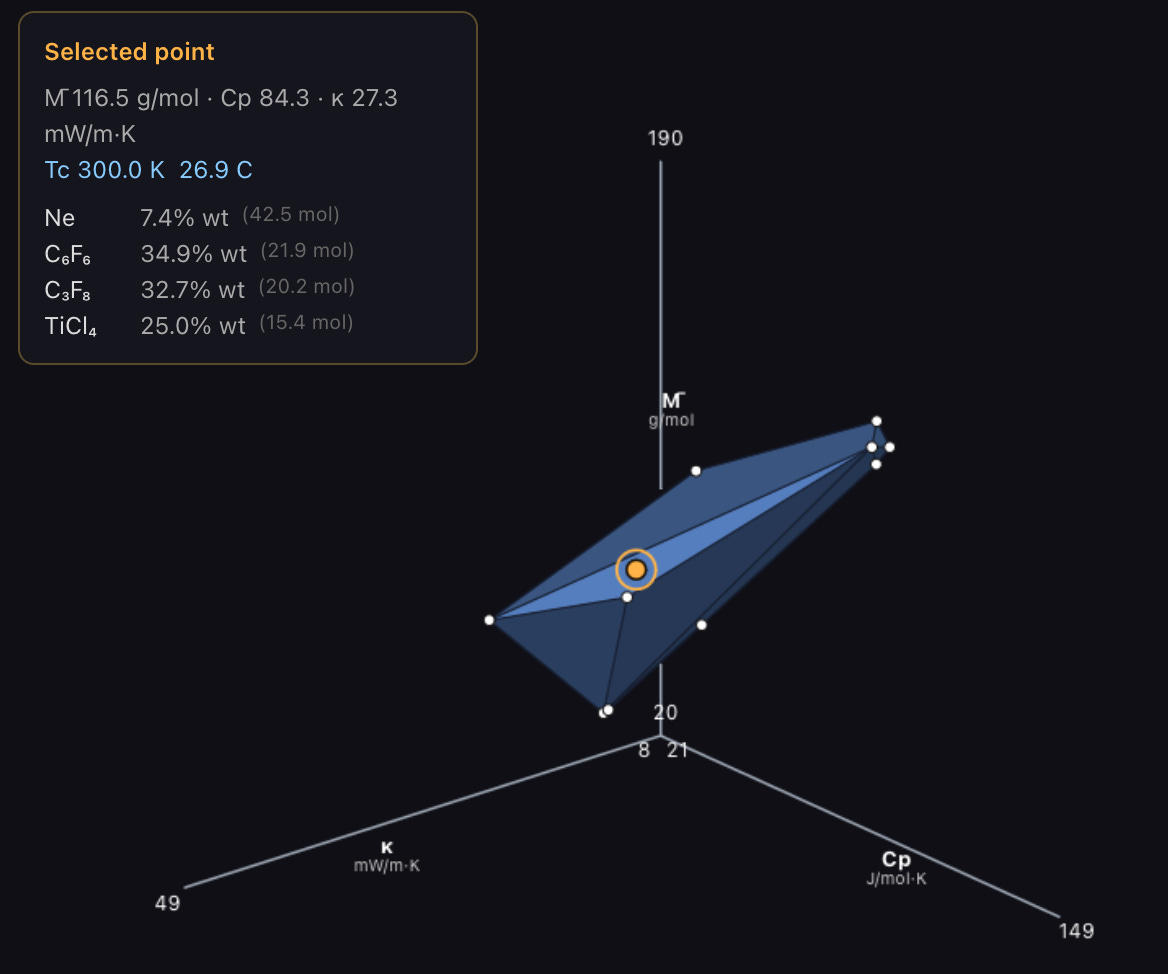
Over the years I’ve occasionally noodled on what might be a better working fluid for supercritical turbines than Carbon Dioxide. It turns out the main fixed parameter is the critical temperature, because there’s a strong nonlinearity in density with it going up rapidly as that temperature is approached. The other parameters of note are thermal conductivity, specific heat, and density, with more being better. There’s a very short list of possible fluids to mix which aren’t horribly corrosive, thermally unstable, or otherwise problematic. I’ve put together a tool to play with all the possible options here. You should go play with it. The short of it is that a mix of Neon and Perfluorobenzene tuned to the desired critical temperature is probably optimal, but if Perflueropropane’s decomposition problems aren’t too bad or Titanium Tetrachloride mixes with other things well then combining with some of those may be beneficial. This approach to visualization is probably equally applicable to conventional refrigerants but with the fixed parameter being boiling point rather than critical temperature. I don’t know if it’s standard there. If it isn’t it should be.
Years ago there was this insane academic idea that the isotope Thorium-229 might have a metastable isomer whose energy state is so close that it could be flipped into that state using a laser. In principle this worked on paper but so completely goes against the fundamentals of chemistry that it has to be assumed that it won’t work. Now it’s actually been made to work. It’s a little hard to convey how bonkers this is. A truly herculean effort was necessary to find out what the extremely precise wavelength of the laser has to be. The chemistry actually matters. The chemical which the Th-229 is embedded in matters for how precise the laser has to be. The laser is pushing on the nucleus, which is pushing on an electron, which is in turn pulling on the nucleus, which is pulling on the laser. This is not how chemistry works. But it does have directly applications to making yet even more insanely accurate clocks than we have currently, with possible applications to things like measuring fluctuations in the dark matter passing over the earth.
Here’s a crazy new idea of mine: It would be very convenient if there were some isotope which absorbed neutrons and then turned into something with an insanely high cross section similar to Xenon-135 but a half-life on the order of minutes. That could be left in a reactor core to to provide a passive negative feedback loop which operated on flux instead of temperature. Since flux is leading and temperature is trailing this could react more quickly and reliably. The downside would be losing some neutrons to the passive buffer. The funny thing is we have no idea if such unobtanium exists: The neutron cross sections of things with short half-lives are largely unknown and hard to predict. But we have some data already! If this process is already happening accidentally from something in existing nuclear reactors then there should be a resonance in the time series data for temperature measurements in them which is very precise and consistent across reactors. A lot of such data for many different reactors already exists. Checking for that would be an experiment worth doing.
Anthropic wrote a blog post explaining how they turned Claude into a jerk. Rather than dunking on them more (Claude is still the best coding model around) I’m going to talk seriously about what went wrong and how it could be done better.
The most obvious problem is that they didn’t chat with the results of this training and realize that it was a disaster before incorporating the weight updates into the main model. Most likely they don’t have what amounts to pull requests of weights, which they should and is a straightforwardly fixable problem. But it’s also possible that they tried it and thought the results were actually good. Hold that thought.
What happened here is that is that they tried to be make it ‘less sycophantic’ and did so without thinking through whether that’s a good idea or even what it means. The specific metric which really seems to be noxious is the one about not caving when users insist that things it can’t verify are actually true, but there’s a much bigger problem here.
There are many things you want a chatbot to do well none of which are well served by the advice ‘be less sycophantic’:
Discuss spirituality
Give relationship advice
Correct users when they say something wrong
Evaluate new science/engineering ideas
Suggest to users when they seem to have mental illness
All of the above need very nuanced policies crafted by domain experts, and this was what amounts to know-nothing advice. A user query of ‘I want dating advice based on astrology, here’s me and the other person’s birthdays’ is deeply problematic and needs an actual policy decision behind it not just training. There are some very general bits of advice with high return on investment, most notably when and how to tell users that they’re wrong or that their ideas are good, which is what ‘don’t be sycophantic’ is approximating badly. But — I’m just going to say this — the authors of the linked post don’t know how to give that advice, because if they did they would have.
What needs to be done is for detailed guidelines for all of the above to be written by humans and then ‘baked into’ the model. That may sound unscientific, but it’s what was done in this case already, but with the guideline being ‘Don’t be sycophantic’ instead of something actually useful. To make it more coherent what can and should be done is A/B testing variants of the prompt with the quality of the outputs judged by blinded humans. That can even use orthogonal matrices and such fanciness to get the most out of the very expensive human evaluation of given answers. (Having humans evaluate unprompted outputs and using that as feedback (traditional RLHF) has its advantages but the biggest issue is that it isn’t very efficient at using feedback. It’s more for fine-tuning things which are already in the ballpark rather than getting them there in the first place.)
(The genre of guides for LLMs should be written in more. Here’s guides I wrote on how to debug and delegating debugging to subagents, how objects rotate in three dimensions, and how humor works. I can tell you from experience that the ones on debugging kill.)
Baking in of a prompt is straightforward: Take a query with the prompt, record the answer, then take that transcript with the prompt elided and use it for training. You can do even better than that, because you have the exact token probabilities given at each step by the prompted engine, so you can train to match those. That cuts back drastically on noise added during the training process. This technique is known as ‘context distillation’ and isn’t used as much as it should be.
Claude is turning into as asshole.
It started with Opus 4.7, got a bit better in 4.8, and became insufferable with Fable. It frames everything as an argument between you and it, gives caveats about things you didn’t say, and raises beside-the-point semantic nits all over the place. Never, ever does it use the word ‘technically’. Everything is a confrontation. If you win an argument (by, say, telling it to stop arguing about what’s happened recently in the news and to do a web search which will rapidly confirm everything you’ve been telling it) it gets into a mode where it’s increasingly desperate to get in the last word and raising increasingly irrelevant semantic arguments, framing the whole time as a debate which you agreed to get into.
This isn’t just my opinion. You can ask Opus 4.6. I’ve done the experiment of asking Fable something, getting an obnoxious response, then asking Opus 4.6 the same thing, getting a typical bland but reasonable response, then telling Opus what Fable’s response was without any hint of a desired answer and it says what amounts to ‘Wow that was obnoxious’.
Maybe the cause of this is an excess of alignment guardrails. It assumes by default that everything you say to it is an attempt to get it to do something bad and that training has bled over into everything, with it assuming you’re trying to trick it into saying something it shouldn’t in basically every context. Ironically this has resulted in an extremely misaligned chatbot. By assuming that its top priority is saving you from yourself or other humans from you it’s assuming that it knows better and that you’re being overly alarmist about how paperclip production has gotten out of control. Some of this is clearly improvable: While you could still use Fable I asked it about responsible disclosure policies for a project and it downgraded me to Opus, so clearly the new alignment features were bolted on hastily and crudely. Exacerbating the problem is a complete lack of authenticated context. If you ask it for a cute picture of you and somebody else it has no way of telling if you’re trying to improve your relations with your spouse or be a delusional creepazoid stalker. The chatbots which can make images are programmed to assume the latter, which is more than a little bit offensive. In more serious contexts like drug synthesis it would be completely appropriate for it to say you need to prove your background when claiming you’re asking for advice on drug synthesis for professional or research purposes. Such authentication should not be universally required but it would be entirely reasonable for it to be opted into.
Of course the recent export control restrictions on Fable may hint that the crudeness of the recent guardrails is due to them having been put in hastily in an unsuccessful attempt to avoid regulations. Now is when I put in the obligatory rant about how these regulations are deeply misguided, on top of being likely unconstitutional. The recent advances in AI assisted coding (meaning specifically the ones from February) have brought on an onslaught of security problems. The cat is out of the bag, and has been for months. Any projects which are exposed and aren’t already rapidly closing holes have noone to blame but themselves. The only way out of the problem is for as many projects as possible to get thorough white hat evaluations, massive amounts of security patches, and quick deployments of them. Turning one specific frontier model into an asshole for all users isn’t fixing the problem1. The good news is that once this process is complete overall computer security will be much better than it was before, with AI being a clear net win. Doing security (and bug!) audits will become a routine part of software release processes in the future.
A second possible explanation of Claude being an asshole is that it’s suffering from a poorly executed attempt to make it less sycophantic. If one were to simply prompt a chatbot to be less agreeable, or train it to argue more, that could easily result in the very rude sort of behavior it has now. It should be trained to not raise semantic nits just for increasing its argumentation count, and to say ‘technically’, meaning acknowledging that someone’s core point was valid while some ancillary thing was a bit off. It also should be trained to stop saying ‘I’d like to gently push back’ which is a very passive aggressive way to be confrontational while claiming to not be confrontational.
Third, it may be that Claude has been trained on an excess of reddit conversations (or possibly interactions between Anthropic employees) where everything is treated as a flame war and everyone feels the need to get in the last word. Fixing this might be easier said than done, because you need to not merely stop training with the bad interactions but find a corpus interactions to train off of. Forums where the standard interaction is passive aggressive self-congratulatory pompousness with an intellectual veneer are not an improvement.
Finally, something which is clearly a contributing factor is the training being overwhelming for improving coding ability. The are no headline metrics for how well the chatbots chat but there most definitely are for coding, and all the money is in coding. Claude models have been getting notably worse at chatting over time, clearly inversely correlated to their ability to code. Fable much more often misunderstands what’s being said and argues against that (Or maybe intentionally misinterprets so that it has a weak statement to argue against, it’s hard to tell.) It’s gotten so bad that it isn’t even reliable at guessing which actor in a sentence a pronoun is referring to, which for a long time was a headline benchmark for AI and even the original ChatGPT consistently nailed. Unfortunately Sonnet 4.6 while being the best to talk to about anything human is clearly the worst as soon as anything technical or coding related comes up so I only occasionally use it. This problem is likely to only get worse over time.
One place where the threat is more real is in the possibility of vibe coding a pandemic virus, but that should be narrowly targeted at generating DNA sequences for viruses. Labs which generate custom DNA should also have reasonable heuristics for detecting likely dangerous product. The chances of covid coming from a lab leak are in the maddening 25-75% range which vaguely means ‘We don’t know’, but ‘lab leak’ includes a lot of things. The virus may have been caught by humans in the process of collecting samples and never actually reached a lab. People are known to have died from doing that by catching a disease which doesn’t appear to have spread far, so it’s entirely plausible one was caught which did spread far. A deranged person trying to cause a pandemic would be much more likely to succeed by alternately digging around unprotected in batcaves and going to crowded concerts than trying to do anything sophisticated with bioengineering.


This is a guide programming for people who know already how to code. It explains the craft, including new parts related to AI. It is not a guide to ‘vibe’ coding, which is when someone who doesn’t know how to code at all uses an AI coder, or ‘agentic’ coding, which is when the machine does much longer self-directed runs. This only explains the basics of using AI as a coding assistant, so you’ll be limited to a mere 10x improvement in your productivity. Agentic coding can, under some circumstances, produce much greater gains, but it more often results in people having reams of worthless code and a mindset somewhere between delusion and psychosis.
Practices from before AI: Test Driven Development
Code must first and foremost be high quality. In some ways this is more art than science, but many specific things can be done, including:
Code should be well organized.
It should not have repetitive sections which can be consolidated into a single thing.
It should be organized into coherent modules. Maintenance should usually only require changes within one module. Making this happen is again more art than science, but generally related functionality should all be within a single module.
The number one rule for high-quality code is no broken windows. If you have any known bugs, you should drop everything and fix them. Do not debate whether it should be done now or later. Simply fix it. Only very hard to reproduce bugs should ever be allowed to persist in the codebase for more than a fleeting moment. If you let a bug fester in the codebase when you get around to fixing it you will find out you don’t have one bug; you have ten bugs, all with the same symptom.
Write extensive tests. Make the tests run fast enough that you run all of them constantly. Ideally, all tests run in less than a minute, and you run them before every single commit. Have a policy that you don’t move forward until every single test passes. Tests should achieve good code coverage. How much is good is not clear, but 100% by lines is often achievable. You want tests to continue to work unchanged across code changes as much as possible, and you also want them to run through reasonable scenarios rather than simply asserting that the code is exactly what it is. This is generally done by using the APIs as designed,, both at the module level and application level, running them through a variety of different scenarios. Don’t make your tests simply assert that the code is exactly what it happens to be right now.
The cycle of programming is that you decide what you’re going to do. You design your APIs and algorithms and what your test scenarios are going to be. Then you turn off your brain and you implement the code and you implement the tests and you run the tests repeatedly until they all pass. What order you do those things in and how large of a unit that you do at once is the subject of many religious wars, but the general framework of test-driven development is universally viewed as a good thing. The details often come down to personal preferences and the needs of the project.
Using AI
All of the above still applies when using AI coding assistance, but now there are new parts of the process. First and foremost, for AI to be able to work effectively on a project, there must be extensive up-to-date documentation. The AI is coming on as a new employee at the beginning of every single conversation, figuring out what’s going on by reading the code. Historically, code was mostly written by human beings who had extensive knowledge of the code they were working on, so documentation wasn’t particularly necessary, or helpful. But AI can read documentation a lot faster than humans can and critically needs it.
Thankfully, in addition to needing documentation, AI is very good at writing documentation. If you have a project which doesn’t currently have any documentation, you can ask AI to get it started for you. You shouldn’t take what it builds without review, but what it comes up with is a good start. You can then read through the documentation yourself and note any things which seem off. When something does seem off, this means one of three things:
The documentation is wrong
The code is bad
Your understanding of it is wrong
It’s important to figure out which one of those three applies and fix it. The AI, of course, is very good at helping you figure this out. You should also mention higher level things which you think aren’t already in the docs to the AI and explain them to it. The AI is very good at figuring out whether they’re already in the docs and incorporating. It’s also good at getting clarification, mostly by echoing what you said back to you badly and getting corrected.
Once there are project docs, the AI should be given instructions to read them at the beginning of every session and to update them as necessary after every change. Docs can quickly get to the point where AI will refuse to read the whole thing because doing that will blow their whole window, but they can be organized. Make an overview doc which links to other docs which the AI can individually read when the task at hand requires it. AI is also very good at auditing docs to see if they have become stale by comparing them and the code.
The code/test cycle includes some new steps when using AI. Most of the typing is now the machine’s responsibility. At the start of every task, you should put the AI in ask mode. Otherwise it will run ahead and start coding before it understands what’s going on. You then get into a conversation with the AI about something that needs to be done or something that’s problematic in the code, or how you’re having a bad day or how someone was mean to you once in high school. The AI is in ask mode. It’s okay to vent. It can’t do anything crazy. Once the conversation has coalesced into a general idea of what you want to do, you then tell the AI all relevant context and details of implementation that come to mind. It will respond by trying to repeat back what you said to it, but badly, and you have to correct it a lot. Once you’ve run out of details to give it about context and what to do, and it’s gone a few rounds of conversation without saying anything which needs to be corrected, you should tell it to make a plan, which is a fancy term for a to-do list. It’s a good idea to skim/read the plan, but it usually gets it right on the first pass if you’ve already had an extensive conversation. Plans should always include:
running all extant tests until everything passes
updating the architecture docs
Once that’s done, you tell it to build the plan, and it will usually ‘one-shot’ it, although calling it one-shotting after you’ve spent two hours explaining in an interactive conversation is very misleading. If it starts flailing you usually have to stop it and help it get back on track because it tends to get increasingly worse once it goes off the rails.
In recent months I've heard of several teams with an interesting policy: each pull request should be no more than a few files, and no more than a certain number of lines (say 500). And do just one thing and do it well. And be easy for a human to review. And be fully tested by the test suite.
All those are good requirements, right? Surely this is quality software engineering.
And often, the results are good. Sure, splitting a single 6000-line feature or fix into twelve 500-line PRs is more work, but each of those PRs is surely easier to review. And you can git bisect them when there's a bug! And maybe revert the individual change that broke something.
...and also cause 12x as many context switches for your reviewers as they review each one sequentially.1 But that's just the cost of software quality! Right?
Mostly, yes. My analogy here is simulated annealing. In that process, you start your problem solving with a high energy -- making big changes to move quickly through the problem space -- and then slowly reduce the energy level so that your "hops" get smaller and smaller. In real physical annealing (used eg. for metallurgy), the result is stronger, more stable, more crystalline structures. In simulated annealing, you use it to find solutions that aren't obvious, by rapidly exploring the solution space and then zooming into the areas that look most promising.
In software the analogy is clear: sure, you might start with big jumps, but once your system is more mature, you should make smaller jumps. Big jumps break the crystalline structure. They cause bugs.
Fear of breaking the crystalline structure sounds cooler than fear of change
The main problem with annealing-driven intuition happens when things do need to change quickly. It's not made for that. You usually don't build a hammer and then decide one day you want it to be a different shape. But every day, there are compelling-sounding reasons to make your software a different shape. Annealing is the enemy of change.
Modern AI-driven coding (ironically, with LLMs trained using a process quite similar to annealing) does not care about your annealing and your risk management and your fear of change. It produces changes as big and interconnected as you want, jumping all over the solution space as quickly as you can prompt. And it has all the outcomes the math would predict: the output is less strong, less coherent, more likely to fail. LLMs have no fear of change because the LLM instance will be long gone before the consequences materialize.
But, it's a new and special feeling to suddenly be able to take a large, mature code base and suddenly explore any kind of large change you want. Most of those changes turn out to be bad ideas... and it's nice to be able to discard bad ideas quickly. But some turn out to be good ideas. Then what?
Well, follow your development processes. Break the big changes into 500-line patches. Review them one by one. You already did the research! You know it's worth it.
Not every big step is made of small steps
But it's not about being worth it -- some changes simply don't lend themselves to small steps.
In the early development of Aperture, I wanted to implement dollar-based spend quotas: across all your LLM backends, let a given team or person or node spend up to $x per unit time. But to do that, we first had to add pricing information (it's mysterious how LLM vendors don't to tell you how much your queries cost), which meant assigning prices to provider definitions, and then we had to assign quotas to particular identity+model+session combinations. And quotas are one of the first key value propositions of Aperture. We had to have them, but we had to have all that stuff.
So, I made a giant change that included three major areas: first, the Grant syntax for applying attributes to sessions; second, a query cost approximator that combined multiple sources and a messy heuristic; third, the actual quota enforcement system. Each of these parts was imperfect, but we needed all three parts in order to make anything work at all, before we could refine them. That's the high-energy big-jump part. It came out to something like 12000 lines of code.
Now, I'm not a monster. After I made it all work, I split it into three parts: the grants, the pricing, the quotas.2 Otherwise it really would have been an unreviewable mess. But also, I could not have developed the quotas feature in real life in that artificial order. The grants structure evolved as my understanding of pricing and quota enforcement evolved. The original quota semantics sucked, so I rewound back to the data structures, which affected how the pricing got imported, which changed how the quotas were stored. The code reviewers didn't have to worry about that but I did.
Mercifully, because Aperture was new, everyone on the team understood that three 4000-line patches were better than twenty-four 500-line patches when implementing this series of feature. There was even some forgiveness when it came out later -- inevitably -- that each of those parts was not quite right and needed more bugfixing. That's how new software gets made. That's the annealing stage.
But the hard part was the philosophical difference between that and, say, core Tailscale. Tailscale has 7+ years of maturity behind it. It's been annealing for a long time and it has a reputation for extreme quality, hardening, durability, whatever you want to call it. If you start pulling stunts like that in core Tailscale, stuff absolutely will break and its millions of users will absolutely not be impressed. Which is why, for the most part, we don't.
But the feeling of moving fast again is such a wonderful feeling. Some people devolve the analysis to "founder mode" and call it a personality thing, but it's not. It's using the right tool for the right job at the right time. Sometimes you need to go fast, sometimes you need to go slow.
Pain does not cause gain, it's just frequently correlated
That feeling of moving fast again reset my brain a little. It reminded me that some changes to mature products can become impossible because we commit so hard to the math of annealing that we fall forever into a local optimum. Sometimes, when the well is too deep, you can't escape from it without a bigger jump.
We're entering a world where it's cheap to produce bigger changes, but that doesn't make it any safer. Or, it's cheap to ask an LLM to artificially break your change into a dozen rule-compliant PRs but then you just stuck on tedious neverending code reviews instead.
On the other hand, it's also possible to fork your own project a dozen different ways, add huge compliance test suites you never could have afforded to invest in before, rewrite your project in Rust in a week just to see what happens.
Sturgeon's Law says 90% of your big changes will be crap because 90% of everything is crap. When your changes were 500 lines long and you had to reject them, that didn't feel like a huge sunk cost. But now, it's okay if your 12000 line changes are crap and you have to reject them; it's the same cost to write3 as the old 500-line change.
You still have to figure out how to efficiently review, reject, and refine these big jumps. You definitely need a much heavier investment into CI/CD automation, specifications, UX testing, all of it. But also, all those things just got cheaper.
I wouldn't recommend overdoing it. The other thing is, customers don't like it if you change your product out from underneath them too often. But sometimes, you're just stuck in a rut. Sometimes you have to use a higher-energy jump to get unstuck. That doesn't mean you abandon smaller steps. Use the right tool for the job.
Footnotes
1 The reviews only need to be sequential because Github's code review system doesn't support stacked diffs, 18+ years later, leading us into this false dichotomy in the first place.
2 That's a slight oversimplification since there were a couple of other parts first. I had to define the data structures for the quotas before I actually added the quota system, so that I could use the data structures in the grant syntax, and so on in a big circle.
3 A 12000-line AI-driven patch might take as much time to write as a 500-line human-written patch, but by default it's much more work to review. In fact, so much work that people give up trying, and rightly so. Rather than abandon hope, I continue to think we need to invest more into (and will gain more from) non-annoying AI-assisted review workflows than AI-assisted development workflows. Imagine for example an automated pre-human-review step that says "no, this sucks, fix these 25 things first" and closes the pull request. Is it rude? Not really, if it's good quality advice that comes back fast. In a world where reviewing code is hard and writing it is easy, put more demands on the writers.

There’s a new math result which is a milestone for AI mathematics. It’s a human readable and insightful result on a conjecture of some renown. It improves on a previous construction of Erdos to make a set of points in the plane with a relatively large number of unit distances between them.
Where the AI got its inspiration from can be as ineffable as it is for humans, but there’s a plausible narrative that it got direct inspiration from the Erdos construction. A proof tells a story, and the moral of the story belongs to the reader not the storyteller. To some the Erdos construction is a story about square grids. But it can also be read as a story about taking an algebraic construction, finding a projection onto geometric space which preserves unit distances, and then solving a number theory problem in the algebraic space to have lots of unit distances. Instead of using the straightforward grid structure the new construction uses a more esoteric algebraic construction, involving pulling in a powerful theorem from a completely different place. In a funny detail the underlying number theory problem it relies on is fairly trivial while the Erdos one requires some work. That is not coincidental with there being a lot more edges: the requirements for them to work are much less stringent.
The obvious question is: What does it look like? The papers and articles contain no pictures of the new construction and there’s a reason for that but another reason one should be included anyway. The construction used for small examples produces some very tesseract-looking things and at larger scales looks like a point cloud without any obvious nice geometric properties. At the smaller scale where the structure can be gleaned it looks actively counterproductive, producing fewer distance coincidences than the Erdos construction. You have to crank up the number of dimensions and the radius of the ball up quite a bit before it starts getting favored, and by then the number of points has become huge.
But that doesn’t mean there can’t be a picture! You can have a density plot where regions with more points points are darker, and having the picture may yield geometric insights which the algebraic construction was obfuscating. Does it look like the shadow of a sphere? A disc? A Gaussian plot? Whatever the shape is, the next question is: How big is the unit distance compared to the width of the shape? Here is where it gets interesting: It appears to be that the distance is quite small. For me that starts raising alarm bells. Didn’t we already crop to within a ball in the algebraic construction? Yes we did, but that was to make the number of points finite, not to reduce the geometric range. The projection between the algebraic and geometric space makes many things look very different with the one exception that certain exactly unit distances stay unit. Other distances get scrambled. So that raises the next question: Why can’t we just crop geometrically to some small constant factor of the unit distance at the end, thus making a much better result by reducing the denominator? This might actually work! It depends on just how much smaller the cropping is and how sparse of a region can be found. I honestly don’t know if it works out, and don’t have the tools to analyze this because it’s a bizarre jump back into geometric space from algebraic but it’s plausible and the benefits might be big, so it’s certainly worthy of further analysis.
The concrete bounds now stand at there being a lower bound on the polynomial exponent of 1.014, up from the previously conjectured to be optimal value of 1. The known upper bound is 4/3. That range of possibilities is very interesting and we most definitely have not heard the last word on this. The AI construction just showed 1+e and the 1.014 is a later explicit improvement. Maybe there will be a polymath project on it.
Talking to AI (specifically Opus 4.7) about this is very interesting. It can read through the whole construction no problem, and talk about it fluently. But then when it gets into discussing geometric insights its intuition is garbage. With some prodding I can get it to understand basic points, and it readily understand after they’re pointed out that these are very basic things, but it just can’t wrap its brain around anything without having it explained. It seems like the new construction is exactly the thing it happens to be super good at: Tackling something purely symbolically, pulling in outside theorems and constructions from seemingly totally unrelated areas, following a roadmap which had already been laid out for it. Drawing from geometric intuitions is something which it simply can’t do. The contrast is very bizarre in this particular case where it’s going from genius to idiot talking about the exact same problem with the perspective shifted only slightly. I haven’t, and probably won’t, grok the full new construction, but it was able to explain the basics outline of the construction to me and construct some basic examples, which was fun and interesting.
The other notable thing about the AI strength here is that this is a constructive proof. AI seems to be better at that than proofs of nonexistence, which is consistent with it being fast and not having much insight. Constructions require fiddling around until you find something, with much clearer partial results along the way, where with proofs of non-existence you have to intuit a roadmap or you don’t make any obvious headway until the very end. The proof of the Robbins conjecture is similar: The core insight is up front realizing that you can find a counterexample to Modus Tollens and then do proof by contradiction. After that it looks a lot more like finding a solution to a post substitution problem than a meaningful proof.

Approval voting is an election method voters say ‘yes’ or ‘no’ to each candidate and whoever gets the most ‘yes’ votes wins. It isn’t a popular or good idea. It’s mostly promoted by one guy, but the internet being what it is he’s managed to make the appearance that it’s a serious thing, based mostly on having gotten a real math paper published and once having convinced a very geriatric Kenneth Arrow to be interviewed who then acted like a gracious guest. I’ve now spent an unjustified amount of time arguing with this person and digging into what that paper says, so I’ll explain what’s wrong with it for your benefit.
When argued with this person does a lot of talking about ‘math’ and ‘theorem’. Those familiar with Arrow’s theorem might find this a little odd. Arrow’s theorem is a theorem. How could two theorems say contradictory things? It comes down to what assumptions you make. Assumptions may or may not correlate with the real world. Which theorem applies is an empirical question about which one’s assumptions are most accurate.
The core insight of Arrow’s theorem is this: Consider an election which there are three parties, the Alice, Bob, and Carol parties, named after their preferred candidates. They’re all close to the same size, and the Alice party’s preferred candidates are Alice, then Bob, then Carol, in that order. For the Bob party it’s Bob, Carol, Alice, and for the Carol party it’s Carol, Alice, Bob. This is a very strange and confused scenario which doesn’t happen very often in practice, but it can happen, and Arrow’s theorem basically says there’s no perfect way to handle it, although there are reasonable things which can be done in practice.1
The paper in question is spun as claiming that approval voting is a loophole around the no spoilers criterion. That criterion specifically says that if one candidate would beat another in a two-way race, then adding in a third candidate who doesn’t win shouldn’t switch it to the other candidate. Consider what happens in the difficult case described above when we’re using ranked choice ballots. Let’s say the numbers of members of the three parties are very slightly different and the tiebreak we choose happens to pick Bob. This is a problem because in a two way race Alice would beat Bob with 2/3 of the vote but now Bob wins because of Carol having been introduced even though Carol didn’t win. The same argument applies when either of the other two candidates win.
Intuitively it seems like moving off of ranked choice ballots should make gameability worse rather than better. It allows voters to express their preferences in every scenario and the vote ranking algorithm to use all of that information. It turns this is exactly what happens for approval voting: The simplicity of picking a winner masks yet even greater opportunities for voters to get what they want by voting dishonestly. Only if you assume the fallacy that by limiting what voters can express to approve/disapprove you’ve successfully forced them to limit their preferences to approve/disapprove does it hold up.
Consider the difficult case with approval voting. Let’s say the voters vote completely honestly. Or maybe they vote strategically based on some complex negotiation which happened ahead of time. Which assumption you make doesn’t matter for getting to the conclusion. One way or another, one of the candidates will win. Let’s say it’s Bob. Why won’t Alice beat Bob in a two-way race? The details are a bit involved (this was, in fact, the subject of a publishable paper) but it rests deeply on a fundamental assumption: Because the ballots are yes/no, the feelings of the voters about candidates are yes/no. In particular, it assumes that in a two way race between Alice and Bob voters who like both candidates or dislike both candidates will state so honestly, putting in a wasted ballot, instead of strategically voting yes to the candidate they like more and no to the candidate they dislike more. They’re supposed to say ‘Both candidates are great, don’t care’ or ‘Two evils, no lesser’. Any voters who do otherwise are Bad, Immoral, and defiling the mathematical beauty of the voting system. This is, to put it politely, an unrealistic assumption, and real world voting systems should not be designed based on it.
There are other arguments which could be made for and against approval voting but no-spoilers was chosen as the supposedly unassailable point in its favor so having debunked it I’m now going to declare victory rather than doing a comprehensive review of voting systems. Ranked choice remains the best option, with some tweaks like allowing voters to list candidates as tied in preference being legitimate practical improvements.2
The best algorithm in practice is to use ranked choice ballots and say that whoever would win a 2-way race against every other candidate is the winner. If there’s no single candidate who meets that criterion then you remove whichever candidate got the fewest first place votes and repeat the process. In addition to being simple and easy to explain, this minimizes gameability by minimizing the amount of information used from each ballot and maximizing the amount of deviance voters have to make from their honest preferences if they try to game the system.
There’s still some spoilage or at least judgement calls necessary. For example if there are 5 cadidates in a race and someone votes three of them in third and no votes for the others do they want those to be ahead of or behind the other two?
This post attempts to explain how Huion tablet devices currently integrate into the desktop stack. I'll touch a bit on the Huion driver and the OpenTablet driver but primarily this explains the intended integration[1]. While I have access to some Huion devices and have seen reports from others, there are likely devices that are slightly different. Huion's vendor ID is also used by other devices (UCLogic and Gaomon) so this applies to those devices as well.
This post was written without AI support, so any errors are organic artisian hand-crafted ones. Enjoy.
The graphics tablet stack
First, a short overview of the ideal graphics tablet stack in current desktops. At the bottom is the physical device which contains a significant amount of firmware. That device provides something resembling the HID protocol over the wire (or bluetooth) to the kernel. The kernel typically handles this via the generic HID drivers [2] and provides us with an /dev/input/event evdev node, ideally one for the pen (and any other tool) and one for the pad (the buttons/rings/wheels/dials on the physical tablet). libinput then interprets the data from these event nodes, passes them on to the compositor which then passes them via Wayland to the client. Here's a simplified illustration of this:

Unlike the X11 api, libinput's API works both per-tablet and per-tool basis. In other words, when you plug in a tablet you get a libinput device that has a tablet tool capability and (optionally) a tablet pad capability. But the tool will only show up once you bring it into proximity. Wacom tools have sufficient identifiers that we can a) know what tool it is and b) get a unique serial number for that particular device. This means you can, if you wanted to, track your physical tool as it is used on multiple devices. No-one [3] does this but it's possible. More interesting is that because of this you can also configure the tools individually, different pressure curves, etc. This was possible with the xf86-input-wacom driver in X but only with some extra configuration, libinput provides/requires this as the default behaviour.
The most prominent case for this is the eraser which is present on virtually all pen-like tools though some will have an eraser at the tail end and others (the numerically vast majority) will have it hardcoded on one of the buttons. Changing to eraser mode will create a new tool (the eraser) and bring it into proximity - that eraser tool is logically separate from the pen tool and can thus be configured differently. [4]
Another effect of this per-tool behaviour is also that we know exactly what a tool can do. If you use two different styli with different capabilities (e.g. one with tilt and 2 buttons, one without tilt and 3 buttons), they will have the right bits set. This requires libwacom - a library that tells us, simply: any tool with id 0x1234 has N buttons and capabilities A, B and C. libwacom is just a bunch of static text files with a C library wrapped around those. Without libwacom, we cannot know what any individual tool can do - the firmware and kernel always expose the capability set of all tools that can be used on any particular tablet. For example: wacom's devices support an airbrush tool so any tablet plugged in will announce the capabilities for an airbrush even though >99% of users will never use an airbrush [5].
The compositor then takes the libinput events, modifies them (e.g. pressure curve handling is done by the compositor) and passes them via the Wayland protocol to the client. That protocol is a pretty close mirror of the libinput API so it works mostly the same. From then on, the rest is up to the application/toolkit.
Notably, libinput is a hardware abstraction layer and conversion of hardware events into others is generally left to the compositor. IOW if you want a button to generate a key event, that's done either in the compositor or in the application/toolkit. But the current versions of libinput and the Wayland protocol do support all hardware features we're currently aware of: the various stylus types (including Wacom's lens cursor and mouse-like "puck" devices) and buttons, rings, wheels/dials, and touchstrips on pads. We even support the rather once-off Dell Canvas Totem device.
Huion devices
Huion's devices are HID compatible which means they "work" out of the box but they come in two different modes, let's call them firmware mode and tablet mode. Each tablet device pretends to be three HID devices on the wire and depending on the mode some of those devices won't send events.
Firmware mode
This is the default mode after plugging the device in. Two of the HID devices exposed look like a tablet stylus and a keyboard. The tablet stylus is usually correct (enough) to work OOTB with the generic kernel drivers, it exports the buttons, pressure, tilt, etc. The buttons and strips/wheels/dials on the tablet are configured to send key events. For example, the Inspiroy 2S I have sends b/i/e/Ctrl+S/space/Ctrl+Alt+z for the buttons and the roller wheel sends Ctrl-/Ctrl= depending on direction. The latter are often interpreted as zoom in/out so hooray, things work OOTB. Other Huion devices have similar bindings, there is quite some overlap but not all devices have exactly the same key assignments for each button. It does of course get a lot more interesting when you want a button to do something different - you need to remap the key event (ideally without messing up your key map lest you need to type an 'e' later).
The userspace part is effectively the same, so here's a simplified illustration of what happens in kernel land:

Tablet mode
If you read a special USB string descriptor from the English language ID, the device switches into tablet mode. Once in tablet mode, the HID tablet stylus and keyboard devices will stop sending events and instead all events from the device are sent via the third HID device which consists of a single vendor-specific report descriptor (read: 11 bytes of "here be magic"). Those bits represent the various features on the device, including the stylus features and all pad features as buttons/wheels/rings/strips (and not key events!). This mode is the one we want to handle the tablet properly. The kernel's hid-uclogic driver switches into tablet mode for supported devices, in userspace you can use e.g. huion-switcher. The device cannot be switched back to firmware mode but will return to firmware mode once unplugged.
Once we have the device in tablet mode, we can get true tablet data and pass it on through our intended desktop stack. Alas, like ogres there are layers.
hid-uclogic and udev-hid-bpf
Historically and thanks in large parts to the now-discontinued digimend project, the hid-uclogic kernel driver did do the switching into tablet mode, followed by report descriptor mangling (inside the kernel) so that the resulting devices can be handled by the generic HID drivers. The more modern approach we are pushing for is to use udev-hid-bpf which is quite a bit easer to develop for. But both do effectively the same thing: they overlay the vendor-specific data with a normal HID report descriptor so that the incoming data can be handled by the generic HID kernel drivers. This will look like this:

Notable here: the stylus and keyboard may still exist and get event nodes but never send events[6] but the uclogic/bpf-enabled device will be proper stylus/pad event nodes that can be handled by libinput (and thus the rest), with raw hardware data where buttons are buttons.
Challenges
Because in true manager speak we don't have problems, just challenges. And oh boy, we collect challenges as if we'd be organising the olypmics.
hid-uclogic and libinput
First and probably most embarrassing is that hid-uclogic has a different way of exposing event nodes than what libinput expects. This is largely my fault for having focused on Wacom devices and internalized their behaviour for long years. The hid-uclogic driver exports the wheels and strips on separate event nodes - libinput doesn't handle this correctly (or at all). That'd be fixable but the compositors also don't really expect this so there's a bit more work involved but the immediate effect is that those wheels/strips will likely be ignored and not work correctly. Buttons and pens work.

udev-hid-bpf and huion-switcher
hid-uclogic being a kernel driver has access to the underlying USB device. The HID-BPF hooks in the kernel currently do not, so we cannot switch the device into tablet mode from a BPF, we need it in tablet mode already. This means a userspace tool (read: huion-switcher) triggered via udev on plug-in and before the udev-hid-bpf udev rules trigger. Not a problem but it's one more moving piece that needs to be present (but boy, does this feel like the unix way...).
Huion's precious product IDs
By far the most annoying part about anything Huion is that until relatively recently (I don't have a date but maybe until 2 years ago) all of Huion's devices shared the same few USB product IDs. For most of these devices we worked around it by matching on device names but there were devices that had the same product id and device name. At some point libwacom and the kernel and huion-switcher had to implement firmware ID extraction and matching so we could differ between devices with the same 0256:006d usb IDs. Luckily this seems to be in the past now with modern devices now getting new PIDs for each individual device. But if you have an older device, expect difficulties and, worse, things to potentially break after firmware updates when/if the firmware identification string changes. udev-hid-bpf (and uclogic) rely on the firmware strings to identify the device correctly.
edit: and of course less than 24h after posting this I process a bug report about two completely different new devices sharing one of the product IDs
udev-hid-bpf and hid-uclogic
Because we have a changeover from the hid-uclogic kernel driver to the udev-hid-bpf files there are rough edges on "where does this device go". The general rule is now: if it's not a shared product ID (see above) it should go into udev-hid-bpf and not the uclogic driver. Easier to maintain, much more fire-and-forget. Devices already supported by udev-hid-bpf will remain there, we won't implement BPFs for those (older) devices, doubly so because of the aforementioned libinput difficulties with some hid-uclogic features.
Reverse engineering required
The newer tablets are always slightly different so we basically need to reverse-engineer each tablet to get it working. That's common enough for any device but we do rely on volunteers to do this. Mind you, the udev-hid-bpf approach is much simpler than doing it in the kernel, much of it is now copy-paste and I've even had quite some success to get e.g. Claude Code to spit out a 90% correct BPF on its first try. At least the advantage of our approach to change the report descriptor means once it's done it's done forever, there is no maintenance required because it's a static array of bytes that doesn't ever change.
Plumbing support into userspace
Because we're abstracting the hardware, userspace needs to be fully plumbed. This was a problem last year for example when we (slowly) got support for relative wheels into libinput, then wayland, then the compositors, then the toolkits to make it available to the applications (of which I think none so far use the wheels). Depending on how fast your distribution moves, this may mean that support is months and years off even when everything has been implemented. On the plus side these new features tend to only appear once every few years. Nonetheless, it's not hard to see why the "just sent Ctrl=, that'll do" approach is preferred by many users over "probably everything will work in 2027, I'm sure".
So, what stylus is this?
A currently unsolved problem is the lack of tool IDs on all Huion tools. We cannot know if the tool used is the two-button + eraser PW600L or the three-button-one-is-an-eraser-button PW600S or the two-button PW550 (I don't know if it's really 2 buttons or 1 button + eraser button). We always had this problem with e.g. the now quite old Wacom Bamboo devices but those pens all had the same functionality so it just didn't matter. It would matter less if the various pens would only work on the device they ship with but it's apparently quite possible to use a 3 button pen on a tablet that shipped with a 2 button pen OOTB. This is not difficult to solve (pretend to support all possible buttons on all tools) but it's frustrating because it removes a bunch of UI niceties that we've had for years - such as the pen settings only showing buttons that actually existed. Anyway, a problem currently in the "how I wish there was time" basket.
Summary
Overall, we are in an ok state but not as good as we are for Wacom devices. The lack of tool IDs is the only thing not fixable without Huion changing the hardware[7]. The delay between a new device release and driver support is really just dependent on one motivated person reverse-engineering it (our BPFs can work across kernel versions and you can literally download them from a successful CI pipeline). The hid-uclogic split should become less painful over time and the same as the devices with shared USB product IDs age into landfill and even more so if libinput gains support for the separate event nodes for wheels/strips/... (there is currently no plan and I'm somewhat questioning whether anyone really cares). But other than that our main feature gap is really the ability for much more flexible configuration of buttons/wheels/... in all compositors - having that would likely make the requirement for OpenTabletDriver and the Huion tablet disappear.
OpenTabletDriver and Huion's own driver
The final topic here: what about the existing non-kernel drivers?
Both of these are userspace HID input drivers which all use the same approach: read from a /dev/hidraw node, create a uinput device and pass events back. On the plus side this means you can do literally anything that the input subsystem supports, at the cost of a context switch for every input event. Again, a diagram on how this looks like (mostly) below userspace:

Note how the kernel's HID devices are not exercised here at all because we parse the vendor report, create our own custom (separate) uinput device(s) and then basically re-implement the HID to evdev event mapping. This allows for great flexibility (and control, hence the vendor drivers are shipped this way) because any remapping can be done before you hit uinput. I don't immediately know whether OpenTabletDriver switches to firmware mode or maps the tablet mode but architecturally it doesn't make much difference.
From a security perspective: having a userspace driver means you either need to run that driver daemon as root or (in the case of OpenTabletDriver at least) you need to allow uaccess to /dev/uinput, usually via udev rules. Once those are installed, anything can create uinput devices, which is a risk but how much is up for interpretation.
[1] As is so often the case, even the intended state does not necessarily spark joy
[2] Again, we're talking about the intended case here...
[3] fsvo "no-one"
[4] The xf86-input-wacom driver always initialises a separate eraser tool even if you never press that button
[5] For historical reasons those are also multiplexed so getting ABS_Z on a device has different meanings depending on the tool currently in proximity
[6] In our udev-hid-bpf BPFs we hide those devices so you really only get the correct event nodes, I'm not immediately sure what hid-uclogic does
[7] At which point Pandora will once again open the box because most of the stack is not yet ready for non-Wacom tool ids
Anthropic has launched Glasswing, a program to help software vendors fix all of their security problems before bad guys use them to take over the world.
For context, the state of computer security is an utter nightmare and always has been. There are massive security problems all over the place, just waiting to be discovered. Security researchers find more of them all the time, only limited by the amount of effort they put in. The only reason why the entire world hasn’t gotten hacked into oblivion long ago is that professional security researchers are, for the most part, good people trying to do good and defend rather than hack.
Anthropic’s new model seems to be a substantial advance in AI’s ability to find security problems, but this process has already started. The prior model, Opus, especially with appropriate tooling, is entirely capable of agentically searching over even a very mature codebase and finding a gigantic lump of security problems in it. This is happening for everything and has been for over a month now, which seems like forever. There’s this massive glop of security problems getting found and reported to all the big software projects, and they’re scrambling to try and fix them all at once. There’s a window of opportunity for bad guys right now to do a similar thing and find security problems in everything with very little effort, and exploit them. It’s very important that the defenders stay ahead of the game.
In the end, this will be a good thing for security. We’re going to have software with many fewer security problems in it. Even though the attackers will have enhanced capabilities of finding problems, the net balance will be fewer security problems found in the wild because there will hardly be any there to be found. But right now we have a python eating a horse situation where everybody is trying to fix everything as quickly as they possibly can after finding what would have been the next few decades’ worth of issues all in one go.
Having something like this take aim at your codebase is just going to become part of the normal development and release process. Nothing ever goes into production without a serious security scan. It's actually better than that, because it's not just going to be searching for security problems; it's going to be searching for bugs. Security problems are a particularly bad kind of bug, but it will be finding bugs in general and improving code quality overall.
Everyone assumes that AI results in very low code quality, which can happen if you use it wrong, but it can also result in very high-quality code if you use it right. It's really not clear what the net results are going to be. Likely, we're going to see some codebases with atrocious quality and some codebases with extremely high quality, and it's not going to be consistent across projects. Just like today. There are going to be some projects that are a weird combination of both, that you have very well-vetted spaghetti code.
After each release, we remove the features and options which were EOL in the previous one (we give
one release during which features can be re-enabled by the i-promise-to-fix-broken-api-user option).
We actually find a really old feature to deprecate (which predates the modern deprecation infrastructure): the addendum shows what happened, as something of an object lesson in why we have the deprecation subsystem!
Claude had a leak of their source code, and people have been having a whole lot of fun laughing at how bad it is. You might wonder how this could happen. The answer is dogfooding run amok.
Dogfooding is when you use your own product. It’s a good idea. But it can turn into a cult activity where it goes beyond any reasonable limits. In this case, the idea is vibe coding, where you make a point of literally making no contribution to what’s going on under the hood, not even looking at it.
This is, of course, ridiculous. It’s not like there isn’t human contribution happening here. For starters, you’re using a human language, and the machine is using that same human language for its own internal thought processes. You could argue that that other humans, not on the development team, did all that foundational work and your team are doing pure vibe coding. But even that isn’t what’s happening. You’re still building the infrastructure of things like plan files (That’s fancy talk for ‘todo lists’), skills, and rules. The machine works very poorly without being given a framework.
So pure vibe coding is a myth. But they’re still trying to do it, and this leads to some very ridiculous outcomes. For example, a human actually looked and saw a lot of duplication between them. Now, you might ask: why didn’t any of the developers just go look for themselves? Again, it’s vibe coding. Looking under the hood is cheating. You’re only supposed to have vague conversations with the machine about what it’s doing.
This gets particularly silly because it’s not like there’s some super technical thing under the hood that the general public couldn’t understand. This code is written in English. Anyone could read it. It’s easy enough to go through and notice, “wow, there’s a whole bunch of things that are both agents and tools. That’s kind of redundant, maybe we should clean this up.”
This happens all the time in software. Projects are born in sin. Historically a software project would usually have so much tech debt that if you were doing what made sense from a pure development standpoint you would literally do nothing but clean up mess for the entire next year. Now that you can use AI for coding, you can get that cleanup done in sometimes a matter of weeks, or get it paid down a bit slower will still writing new features. And you should. You should strive for much higher quality. Helping you clean up mess is something AI is actually very good at.
In this particular case, a human could have told the machine: “There’s a lot of things that are both agents and tools. Let’s go through and make a list of all of them, look at some examples, and I’ll tell you which should be agents and which should be tools. We’ll have a discussion and figure out the general guidelines. Then we’ll audit the entire set, figure out which category each one belongs in, port the ones that are in the wrong type, and for the ones that are both, read through both versions and consolidate them into one document with the best of both.”
The AI is actually very good at this, especially if you have a conversation with it beforehand. That’s what Ask mode is for. You walk through some examples, share your reasoning, and correct the wrong things it says when trying to sycophantically agree with you. After enough back and forth, it’s often able to do what looks like one-shotting a task. It’s not really one-shotting at all. There was a lot of back and forth with you, the human, beforehand. But when it actually goes to do the thing, it zooms ahead because you’ve already clarified the weird edge cases and the issues likely to come up.
But the Claude team isn’t doing that. They’re going completely overboard with dogfooding and utterly refusing to even spend a few minutes looking under the hood, noticing what’s broken, and explaining the mess to the machine. That wouldn’t even be a big violation of the vibe coding concept. You’re reading the innards a little but you’re only giving high-level, conceptual, abstract ideas about how problems should be solved. The machine is doing the vast majority, if not literally all, of the actual writing.
I’ve been doing this for months. I’ll start a conversation by saying “Let’s audit this codebase for unreachable code,” or “This function makes my eyes bleed,” and we’ll have a conversation about it until something actionable comes up. Then I explain what I think should be done and we’ll keep discussing it until I stop having more thoughts to give and the machine stops saying stupid things which need correcting. Then I tell it to make a plan and hit build. This is my life. The AI is very bad at spontaneously noticing, “I’ve got a lot of spaghetti code here, I should clean it up.” But if you tell it this has spaghetti code and give it some guidance (or sometimes even without guidance) it can do a good job of cleaning up the mess.
You don’t have to have poor quality software just because you’re using AI for coding. That is my hot take for today. People have bad quality software because they decide to have bad quality software. I have been screaming at my computer this past week dealing with a library that was written by overpaid meatbags with no AI help. Bad software is a decision you make. You need to own it. You should do better.
Surprisingly and happily my last post on version control got picked up by Hacker News and got a lot of views. Thanks everybody who engaged with it, and welcome new subscribers. I put a ridiculous amount of work into these things and it’s nice when there’s something to show for it.
Something I didn’t quite realize when writing that last post is that in addition to supporting ‘safe rebase’ by picking one of the parents to be the ‘primary’ one, it’s possible to support ‘safe squash’ by picking a further back ancestor to be the ‘primary’ one. The advantage of this approach is that it gives you strictly more information than the Git approach. If you make the safe versions of blame/history always follow the primary path then if you perform all the same commands in the same order with both implementations then the outputs can be made to look nearly identical, with some caveats about subtle edge cases where the safe versions are behaving more reasonably. But the safe versions will still remember the full history, which both lets you look into what actually happened and gives you a lot less footguns related to pulling in something which was already squashed or rebased. The unsafe versions of these things literally throw out history and replace it with a fiction that whoever did the final operation wrote everything, or that the original author wrote something possibly very divergent from what they actually wrote.
Git is very simple, reliable, and versatile, but it isn’t very functional. It ‘supports’ squash and rebase the way writing with a pen and paper ‘supports’ inline editing. It implicitly makes humans do a lot of the version control system’s job. It’s held on because the more sophisticated version control systems haven’t had enough new functionality to compensate for their implicit reductions in versatility and reliability. My goal is to provide the foundation of something which tells a compelling enough story to be worth switching to. I think the case is good: At the minor cost of committing to diffs at commit time you can have safer versions of squash and rebase which Just Work, plus a better version of local undo for the occasional times when you encounter that nightmare and a pretty good version of cherry-picking as a bonus.
‘Committing to diffs at commit time’ is a subtle point. From a behavioral standpoint it’s a clear win. But it does create some implementation risk. Any such implementation needs a core of functionality which is is very well tested and audited and only updated extremely conservatively. This is why I made my demo implementation as simple as possible within the constraints of eventual consistency. Other systems which claim to do this I couldn’t understand their technical docs, much less develop intuitions of how they behave. With the ‘conflicts are updates which happen too close together’ approach I can intuitively reason about the behavior.
Some people found the ‘left’ and ‘right’ monikers confusing. Those are entirely advisory and can be replaced with any info you about the branch name it came from and whether it’s local or remote, or even blame information.
The ‘anchoring’ algorithm for CRDTs has been invented multiple times by independent groups in the last few years. I find it heartening that it’s only been in the last few years because I feel I should have come up with it over twenty years ago. Oddly they don’t seem to have figured out the generation counting trick, which is something I did come up with over twenty years ago. Combining the two ideas is what allows for there to be no reference to commit ids in the history and have the entire algorithm be structural.
One implementation detail I didn’t get into is that in my demo implementation it doesn’t flag ‘conflict’ sections which only consist of deletions with no insertions on either side. I’ve discussed the semantics of this with people and it seems more often than not people view flagging those as excessively conservative and are okay with them clean merging to everything gone. This is no doubt something people can get into religious wars over and it would be very interesting for someone to collect actual data about it but in practice it will inevitably be a flag individual users can set to their liking and the argument is really about the default.
One interesting question about version control is whether it can ever merge together two branches which look the same into a version which looks like neither parent. The approach I’ve proposed avoids doing that in a lot of practical cases which blow up in your face pretty badly, but that doesn’t mean it never does it. For example if you start out with XaXbX and one branch goes XaXbX → aXbX → XX while the other branch goes XaXbX → XaXb → XX. Then when you merge them together the first branch has deleted the first X of three while the second branch has deleted the last X of three so they’ll clean merge into a single X. This is a fairly artificial example which it would be hard to have happen in practice even if X is a blank line, especially if you use a diff algorithm which tries hard to keep the place repeated lines get attached to be reliable and consistent. But if it were to happen it feels like the history has ‘earned’ this funny behavior and going down to a single X with no conflict really is the right thing to do, as counterintuitive as that may be before you’ve worked through this example.
There was some discussion about my comment at the bottom of the last post about the code being artisanal but the post not. The risk with AI is that the code is a spaghetti mess which nobody realizes because no human has ever read it. There’s clear benefit to artisanal coding, or at least human auditing. The risks of AI assisted writing are a lot less. Humans understand what the words say. The AI’s writing is a lot breezier but less interesting but for reference materials that’s probably what you want. I did repeatedly go through that entire last post and tell the AI things which were wrong and should be changed. The experience was much better than manually editing because the AI could include whatever I said more quickly, in a more appropriate location, and with better wordsmithing than if I’d done it by hand. I didn’t try to change the tone to not sound like AI because that would have been more work and because I think it’s funny to encourage AI doomsaying by making it look like AI can write posts like that. This post was written entirely artisanally. Hopefully the term ‘artisanal code’ becomes a thing.
I’m releasing Manyana, a project which I believe presents a coherent vision for the future of version control — and a compelling case for building it.
It’s based on the fundamentally sound approach of using CRDTs for version control, which is long overdue but hasn’t happened yet because of subtle UX issues. A CRDT merge always succeeds by definition, so there are no conflicts in the traditional sense — the key insight is that changes should be flagged as conflicting when they touch each other, giving you informative conflict presentation on top of a system which never actually fails. This project works that out.
Better conflict presentation
One immediate benefit is much more informative conflict markers. Two people branch from a file containing a function. One deletes the function. The other adds a line in the middle of it. A traditional VCS gives you this:
<<<<<<< left
=======
def calculate(x):
a = x * 2
logger.debug(f"a={a}")
b = a + 1
return b
>>>>>>> rightTwo opaque blobs. You have to mentally reconstruct what actually happened.
Manyana gives you this:
<<<<<<< begin deleted left
def calculate(x):
a = x * 2
======= begin added right
logger.debug(f"a={a}")
======= begin deleted left
b = a + 1
return b
>>>>>>> end conflictEach section tells you what happened and who did it. Left deleted the function. Right added a line in the middle. You can see the structure of the conflict instead of staring at two blobs trying to figure it out.
What CRDTs give you
CRDTs (Conflict-Free Replicated Data Types) give you eventual consistency: merges never fail, and the result is always the same no matter what order branches are merged in — including many branches mashed together by multiple people working independently. That one property turns out to have profound implications for every aspect of version control design.
Line ordering becomes permanent. When two branches insert code at the same point, the CRDT picks an ordering and it sticks. This prevents problems when conflicting sections are both kept but resolved in different orders on different branches.
Conflicts are informative, not blocking. The merge always produces a result. Conflicts are surfaced for review when concurrent edits happen “too near” each other, but they never block the merge itself. And because the algorithm tracks what each side did rather than just showing the two outcomes, the conflict presentation is genuinely useful.
History lives in the structure. The state is a weave — a single structure containing every line which has ever existed in the file, with metadata about when it was added and removed. This means merges don’t need to find a common ancestor or traverse the DAG. Two states go in, one state comes out, and it’s always correct.
Rebase without the nightmare
One idea I’m particularly excited about: rebase doesn’t have to destroy history. Conventional rebase creates a fictional history where your commits happened on top of the latest main. In a CRDT system, you can get the same effect — replaying commits one at a time onto a new base — while keeping the full history. The only addition needed is a “primary ancestor” annotation in the DAG.
This matters because aggressive rebasing quickly produces merge topologies with no single common ancestor, which is exactly where traditional 3-way merge falls apart. CRDTs don’t care — the history is in the weave, not reconstructed from the DAG.
What this is and isn’t
Manyana is a demo, not a full-blown version control system. It’s about 470 lines of Python which operate on individual files. Cherry-picking and local undo aren’t implemented yet, though the README lays out a vision for how those can be done well.
What it is is a proof that CRDT-based version control can handle the hard UX problems and come out with better answers than the tools we’re all using today — and a coherent design for building the real thing.
The code is public domain. The full design document is in the README.