This feed omits posts by rms. Just 'cause.
And you can get a discounted seated "Season Pass" ticket that gets you a seat at all five events through the end of the year!




As just a few examples of "great movie, but bad fit": Aliens, Strange Days, The Thing. They're great movies! But they aren't party movies. They're too good.
On the other end of the scale is the obscurity problem: I'd love to do Barbarella, Danger Diabolik, Dr. Phibes, but nobody's heard of them. The 6 people who would show up (8, counting me and Kingfish) would love it, but it would be a flop.
Anyway, we've got a list, and if these next five movies go well and we start getting some regulars, maybe we'll be able to dip into the backstock as well. So if you want us to keep doing this kind of thing... vote by showing up.

Happy July 4th! For those of us around the world contemplating independence, it's a good day to think about how we came to rely on expensive cloud infrastructure for our fundamental computing needs.
With that in mind, here is my latest toy project: an open source tool that makes replicating, forking, sharing, and running container snapshots fast and easy across cloud and personal devices.
It's fun to play with, especially on bare metal hardware you run at home, or rent from a provider like Hetzner or OVH. Or, because it uses Tailscale, why not all of them in a single mesh?
There's a lot more to say but I don't have time right now. Details are in the README.
I will say this: humans and AI agents both want the same things when they're trying to get work done. Ephemeral containers aren't really it. But how about unlimited disk space, fast CPUs, an undo button, and the ability to move to whatever provider offers the best hardware at the best price? That's more like it.
Go visit thundersnap on github and tell me what you think!
Please be aware that I have the most comprehensive collection of jokes of this formation, so you cannot stump me, that's not what I'm asking. I have 100% heard your joke before. I just want to hear your best formation. Bring it.
Previously, previously, previously, previously, previously, previously.

The 40th Annual Conference on Neural Information Processing Systems (NeurIPS) -- which is slated to take place in Sydney, Australia, in December 2026 -- bans peer reviewers from uploading papers they referee to AI chatbots, as the practice breaches confidentiality. [...] To enforce the policy and catch illicit AI use in peer review, the event's organizers have included deliberately concealed instructions for large language models (LLMs) in papers sent out for peer review.
The instructions tell an LLM to use telltale phrases -- such as "This work addresses the central challenge" and "The claims of the paper" -- in a peer-review report. [...]
"Designing a trap that presumes bad faith corrodes the relationship the whole system depends on," Sören Auer, a computer scientist at Leibniz University Hannover, wrote on LinkedIn. "You do not build a healthy reviewing culture by treating your reviewers as suspects."
But others see merits in the approach. A similar prompt-injection effort has caught hundreds of reviewers misusing LLMs in submissions for next week's 43rd International Conference on Machine Learning (ICML 2026) in Seoul, South Korea, according to Nihar Shah, a computer scientist at Carnegie Mellon University and scientific integrity chair of that conference.
Culture of trust, uh huh.
In 1929, Secretary of State Henry Stimson closed down the "black chamber" -- the State Department's code‐breaking office -- on the principle that the way to make men and nations trustworthy was to trust them. As he later told aide McGeorge Bundy, "Gentlemen do not read each other's mail."




Two ICE agents harassed a poll worker on Election Day, demanding she remove social media posts they claimed threatened federal agents.
Paigelynne Gonyea, a poll worker in Syracuse, New York, said she received a phone call Tuesday from two ICE agents asking to meet with her. Not wanting to meet with them alone, she invited them into her workplace. "I've seen the news, especially in Minnesota," she said. "And I didn't want anything to happen to me at all."
The ICE agents arrived with copies of her social media posts and driver's license, and handed her a warning notice alerting her that they were investigating her for allegedly threatening ICE personnel. "They tried to scare me into signing it while I was working," she said. The agents told her to "remove and/or discontinue" the behavior, according to the notice, which Gonyea shared on Instagram. [...]
Ross, who was only placed on three days of administrative leave for shooting Good in the head, chest, and arm, faced virtually no consequences for killing an innocent woman in broad daylight. It appears that federal law enforcement now view pleas for actual justice as some kind of threat. [...]
Gonyea's experience is just the latest example of how far federal law enforcement is willing to go to silence critics of President Donald Trump's mass deportation efforts. Earlier this week in Texas, a man received a 30-year prison sentence for transporting left-wing zines linked to a protest at ICE's Prairieland Detention Facility. Others involved in the protest received sentences of up to 50 years.
Previously, previously, previously, previously, previously, previously, previously.



Please enjoy jwz mixtape 259.

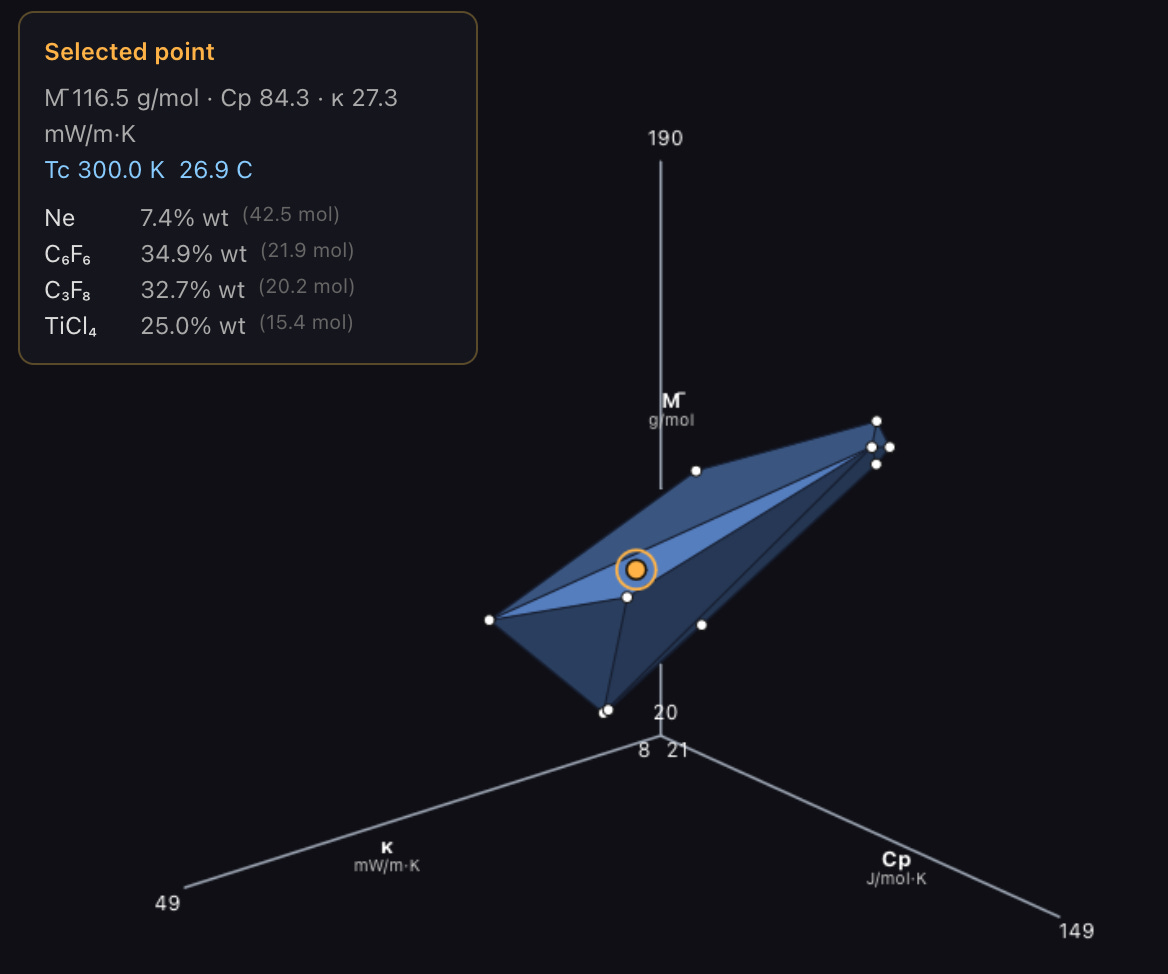
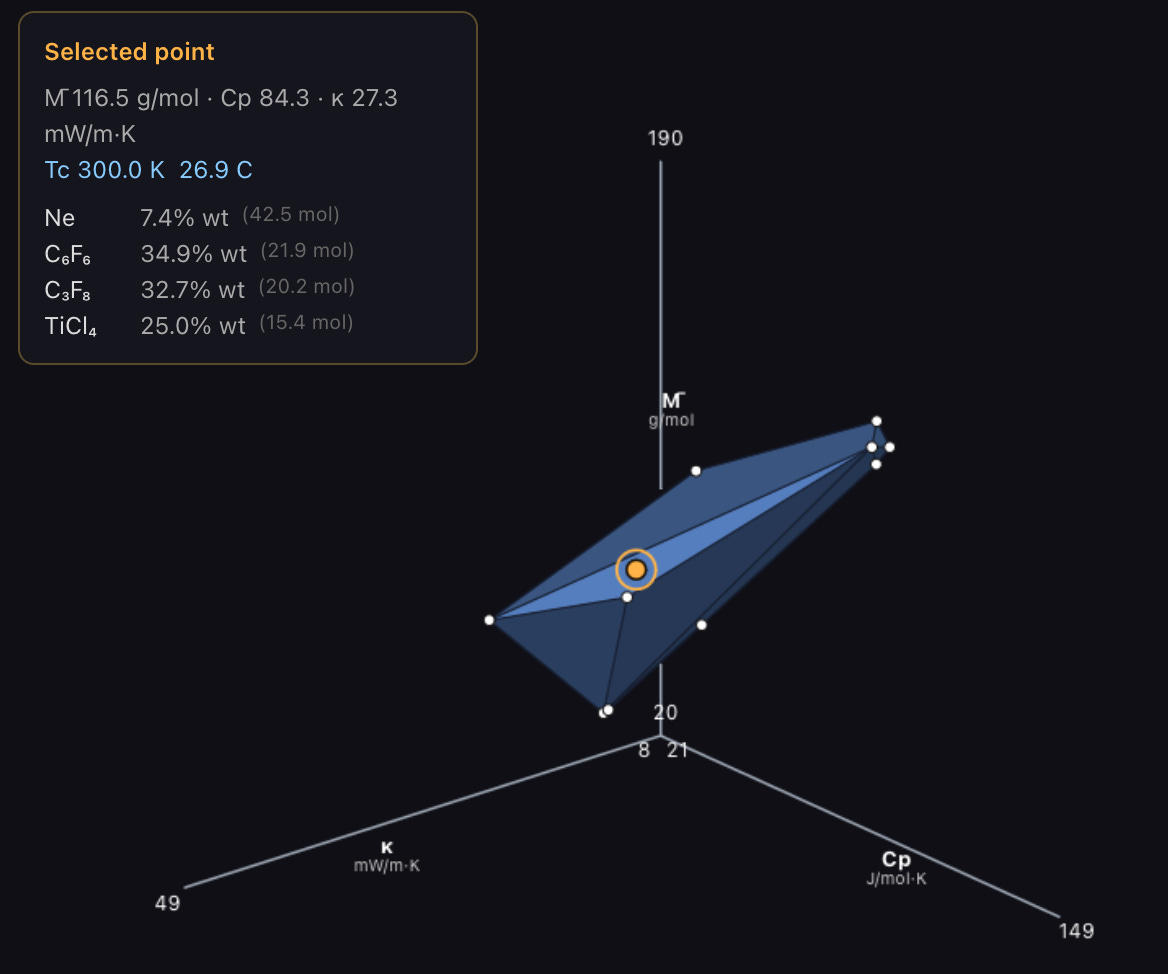
Over the years I’ve occasionally noodled on what might be a better working fluid for supercritical turbines than Carbon Dioxide. It turns out the main fixed parameter is the critical temperature, because there’s a strong nonlinearity in density with it going up rapidly as that temperature is approached. The other parameters of note are thermal conductivity, specific heat, and density, with more being better. There’s a very short list of possible fluids to mix which aren’t horribly corrosive, thermally unstable, or otherwise problematic. I’ve put together a tool to play with all the possible options here. You should go play with it. The short of it is that a mix of Neon and Perfluorobenzene tuned to the desired critical temperature is probably optimal, but if Perflueropropane’s decomposition problems aren’t too bad or Titanium Tetrachloride mixes with other things well then combining with some of those may be beneficial. This approach to visualization is probably equally applicable to conventional refrigerants but with the fixed parameter being boiling point rather than critical temperature. I don’t know if it’s standard there. If it isn’t it should be.
Years ago there was this insane academic idea that the isotope Thorium-229 might have a metastable isomer whose energy state is so close that it could be flipped into that state using a laser. In principle this worked on paper but so completely goes against the fundamentals of chemistry that it has to be assumed that it won’t work. Now it’s actually been made to work. It’s a little hard to convey how bonkers this is. A truly herculean effort was necessary to find out what the extremely precise wavelength of the laser has to be. The chemistry actually matters. The chemical which the Th-229 is embedded in matters for how precise the laser has to be. The laser is pushing on the nucleus, which is pushing on an electron, which is in turn pulling on the nucleus, which is pulling on the laser. This is not how chemistry works. But it does have directly applications to making yet even more insanely accurate clocks than we have currently, with possible applications to things like measuring fluctuations in the dark matter passing over the earth.
Here’s a crazy new idea of mine: It would be very convenient if there were some isotope which absorbed neutrons and then turned into something with an insanely high cross section similar to Xenon-135 but a half-life on the order of minutes. That could be left in a reactor core to to provide a passive negative feedback loop which operated on flux instead of temperature. Since flux is leading and temperature is trailing this could react more quickly and reliably. The downside would be losing some neutrons to the passive buffer. The funny thing is we have no idea if such unobtanium exists: The neutron cross sections of things with short half-lives are largely unknown and hard to predict. But we have some data already! If this process is already happening accidentally from something in existing nuclear reactors then there should be a resonance in the time series data for temperature measurements in them which is very precise and consistent across reactors. A lot of such data for many different reactors already exists. Checking for that would be an experiment worth doing.
As with the Spencer archives, I hope this trend of people unearthing their 36-year-old VHS tapes continues...

- The Bride! (2026):
Frankenstein is having a moment. This one is absolutely amazing! Where Poor Things was Arthouse Frankenstein, this is more of a Grindhouse Frankenstein. It wears all of the references. There's a little bit of Frankenhooker, a little bit of Young Frankenstein, a little Salome, a little Bonnie and Clyde a hell of a lot of Natural Born Killers, wrapped up in a bow of feminist cannibalism. I spent a lot of this movie with my mouth open, thinking "oh wow, you went there".Best movie of the year so far.
- Mother Mary (2026):
Starts off as a reunion between a fancy pop star and her estranged dressmaker, then takes some very surreal and witchy turns. The cinematography is great, the songs are great. They rubbed a bunch of Charli XCX and Iris Van Herpen over it.Second best movie of the year.
- The Peripheral (2022):
On a rewatch, still absolutely brilliant. A friend was watching it for the first time (impetus for my rewatch) and once Lowbeer showed up I said, "Most terrifying person in the show. In a rich field of badasses." It is an absolute tragedy that the planned second season was scuttled by COVID.Because I couldn't get enough I then re-read both novels, The Peripheral and Agency, and though the show is A+, they remain even better.
- Pretty Lethal (2026):
Some ballerinas break down on the road, and oh no, the nearest cabin in the woods happens to be a ballet themed cabaret, and oh no, their only dry clothes are their tutus, and oh no, the impresario is a mobster washed up ballerina -- wait is that Uma Thurman, what is she doing slumming in this trash -- and oh no, now it's a gang war and ballerinas are uniquely skilled at murder.Anyway if you have ever thought, "Oh, I could never be a writer", remember that someone got paid to write this. And dozens of people said, "Yeah, sure, good enough."
- The Ugly Stepsister (2026):
A pretty great, gory take on Cinderella. They set you up to wonder which of these character is going to end up being sympathetic, but nope, they're all horrid grifters, and there is a heavy emphasis on the details of 17th Century cosmetic surgery techniques, including tapeworm dieting. And the toe thing, obviously. - Sew Torn (2024):
A weirdo seamstress sees the opportunity for a perfect crime and it all goes Coen-shaped; and then they do the Run Lola Run thing and play it out three more different ways. Also the weirdo seamstress is like the MacGuyver of sewing; she never saw a problem that couldn't (shouldn't) be solved with 3 bobbins and 100' of thread. It's pretty great. - Ready or Not 2 (2026):
Absolutely fantastic. Even better than the first one. Samara Weaving kills a bunch of billionaire satanists. Shit man that's all you had to say. Buffy is in it, and also Cronenberg. ("You made your sale, son!") - Exit 8 (2025):
Guy is trapped in an endless subway station loop, with "SCP"-style vibes. It's very creepy and pretty scary without anything graphical happening, or honestly much of anything at all. Well made, unsatisfying ending. - Stop Making Sense (1984):
I had not watched this in years and god damn does it hold up. This is the second best* concert film ever made. As I was putting together my nuclear war mixtape I briefly considered including Life During Wartime and that led me to realize that I had never gotten around to ingesting the movie into the DNA Pizza music video rotation. So I did that. Anyway there was a recent-ish 4K remaster that is killer, and has director's commentary and lots of cool extras.* Number one of course is Home of The Brave and number three of course is Urgh! A Music War. I will not be taking any questions.
- The Yeti (2026):
They put together a D&D party of adventurers for a rescue mission to the Alaska Territory, 1946. Extreme Marion Ravenwood feel. Pulpy goodness, but the second half drags a bit.(Marion Ravenwood movie when?)
- How To Get To Heaven From Belfast (2026):
Three idiot 40 year old women try to solve a murder that has something to do with some murderous and/or witchy antics they got up to in high school. It's pretty funny and I liked the characters, but it does the Netflix Episode seven flashback exposition thing (this time in episode 6) and when it did, the reveal of the mystery was just so stupid that I didn't care any more. Squandered. SQUANDERED.Also, in this entire show full of quite foul-mouthed Irish people, never once was the word "cunt" deployed, and honestly, that's just implausible. I feel the feathery touch of a US Netflix exec on the script.
- They Will Kill You (2026):
Final Girl does a John Wick on a Dakota Building full of immortal, regenerating Satanists. Pretty much one arterial spray per minute. Does what it says on the can. - Daredevil, Born Again S02:
It's always good when you get more Kingpin. And they stuck the landing with the finale. Thumbs up. - Pretty Ugly, The Story Of The Lunachicks (2026):
Honestly I wasn't that familiar with The Lunachicks but that won't stop me from watching a documentary about an early 90s punk band. This was pretty good. - Spider Noir (2026):
I find Nicholas Cage's movies pretty uneven -- ok, mostly bad -- but rarely boring. This is a snore. How did they make it so boring? In the last 2 eps they finally kinda-sorta let Cage off the chain but it was too little too late. - Hokum (2026):
Decent haunted hotel story with Adam Scott from Severance. - Vampires of the Velvet Lounge (2026):
Pervert vampires who run an absinthe bar get their victims on Tinder. I started watching this thinking, "This is going to be too cheesy to make it more than a few minutes", but it's actually pretty fun. It has no budget, but the look of the green-fairy vamps is pretty cool. (And these are some ...relatively... big names for what's basically a Troma movie, how did this happen?) - The Voices of Our Mother (2026):
Bad moms, generational trauma, demonic possession. Not bad. - The Testaments (2026):
Handmaid's Babies. Not bad but could have moved the plot along much faster. - Margo's Got Money Troubles (2026):
Elle Fanning gets knocked up and does Onlyfans. Her trashy mom is Michelle Pfeiffer. Raunchy and hilarious, but content warning for having too much baby. - My Animal (2023):
Love story about small-town Canadian lesbians in the 80s, hockey, alcoholic mom. Oh also one of them's a werewolf. It's great. As I'm sure I've mentioned before, the best werewolf genre is "small town werewolf". Killer contemporary-synthwave soundtrack. Also, to my great surprise, the font used in the titles and credits is the DNA Lounge font (Helvetica Neue LT Com 93 Black Extended, I'd know it anywhere.) - Widow's Bay (2026):
The guy from The Americans is the sad-sack mayor of a haunted town on an isolated island, trying to get tourist trade with a minimum of murders. It's very... Netflixxy. Not bad, but it takes forever to get going and drags anything of consequence out until the very last minute. - Slanted (2025):
A Chinese-American girl gets magical-surgery to turn white. It starts off a bit Mean Girls / Freaky Friday and then goes to some body horror places, and has a few twists that I did not see coming. Really fun.

"Serhiy was great at flirting," his commander told me. "Guys in our team started asking him for dating advice." Shortly after Achmad sent that photograph, the coordinates it revealed were struck by a Ukrainian drone. [...]
Any phone purchased inside the occupied territories is useless for resistance work. Devices sold there come preloaded with monitoring software developed by Russian intelligence. That app is called Druge -- Друг -- which means "friend" in Russian.
Druge monitors communications, photographs, and location data, relaying all of it back to Russian intelligence. [...] At checkpoints, Russian soldiers examine every phone. Not having Druge installed is a red flag to them; having an encrypted app, such as Signal, guarantees a phone's owner a trip to the basement. [...]
Few resistance agents have professional training. Most learn on the job. Partisans pass around hard-copy tradecraft manuals to avoid using vulnerable digital channels. Within Kherson's partisan brigade, one of the most sought-after is a Soviet-era handbook describing CIA catfishing tactics in Africa during the Cold War. No online version exists, but a well-worn original circulates among the resistance.
"Your CIA was good at this," Dmytro said. "You bastards knew how to use sex."
Several Ukrainian print shops have developed methods for hiding instruction manuals inside best-selling books. A guard at a Russian checkpoint, thumbing through an artificially tattered paperback, will likely have no idea that some of the pages explain how to kill him.
Previously, previously, previously, previously, previously, previously.

Anthropic wrote a blog post explaining how they turned Claude into a jerk. Rather than dunking on them more (Claude is still the best coding model around) I’m going to talk seriously about what went wrong and how it could be done better.
The most obvious problem is that they didn’t chat with the results of this training and realize that it was a disaster before incorporating the weight updates into the main model. Most likely they don’t have what amounts to pull requests of weights, which they should and is a straightforwardly fixable problem. But it’s also possible that they tried it and thought the results were actually good. Hold that thought.
What happened here is that is that they tried to be make it ‘less sycophantic’ and did so without thinking through whether that’s a good idea or even what it means. The specific metric which really seems to be noxious is the one about not caving when users insist that things it can’t verify are actually true, but there’s a much bigger problem here.
There are many things you want a chatbot to do well none of which are well served by the advice ‘be less sycophantic’:
Discuss spirituality
Give relationship advice
Correct users when they say something wrong
Evaluate new science/engineering ideas
Suggest to users when they seem to have mental illness
All of the above need very nuanced policies crafted by domain experts, and this was what amounts to know-nothing advice. A user query of ‘I want dating advice based on astrology, here’s me and the other person’s birthdays’ is deeply problematic and needs an actual policy decision behind it not just training. There are some very general bits of advice with high return on investment, most notably when and how to tell users that they’re wrong or that their ideas are good, which is what ‘don’t be sycophantic’ is approximating badly. But — I’m just going to say this — the authors of the linked post don’t know how to give that advice, because if they did they would have.
What needs to be done is for detailed guidelines for all of the above to be written by humans and then ‘baked into’ the model. That may sound unscientific, but it’s what was done in this case already, but with the guideline being ‘Don’t be sycophantic’ instead of something actually useful. To make it more coherent what can and should be done is A/B testing variants of the prompt with the quality of the outputs judged by blinded humans. That can even use orthogonal matrices and such fanciness to get the most out of the very expensive human evaluation of given answers. (Having humans evaluate unprompted outputs and using that as feedback (traditional RLHF) has its advantages but the biggest issue is that it isn’t very efficient at using feedback. It’s more for fine-tuning things which are already in the ballpark rather than getting them there in the first place.)
(The genre of guides for LLMs should be written in more. Here’s guides I wrote on how to debug and delegating debugging to subagents, how objects rotate in three dimensions, and how humor works. I can tell you from experience that the ones on debugging kill.)
Baking in of a prompt is straightforward: Take a query with the prompt, record the answer, then take that transcript with the prompt elided and use it for training. You can do even better than that, because you have the exact token probabilities given at each step by the prompted engine, so you can train to match those. That cuts back drastically on noise added during the training process. This technique is known as ‘context distillation’ and isn’t used as much as it should be.
Claude is turning into as asshole.
It started with Opus 4.7, got a bit better in 4.8, and became insufferable with Fable. It frames everything as an argument between you and it, gives caveats about things you didn’t say, and raises beside-the-point semantic nits all over the place. Never, ever does it use the word ‘technically’. Everything is a confrontation. If you win an argument (by, say, telling it to stop arguing about what’s happened recently in the news and to do a web search which will rapidly confirm everything you’ve been telling it) it gets into a mode where it’s increasingly desperate to get in the last word and raising increasingly irrelevant semantic arguments, framing the whole time as a debate which you agreed to get into.
This isn’t just my opinion. You can ask Opus 4.6. I’ve done the experiment of asking Fable something, getting an obnoxious response, then asking Opus 4.6 the same thing, getting a typical bland but reasonable response, then telling Opus what Fable’s response was without any hint of a desired answer and it says what amounts to ‘Wow that was obnoxious’.
Maybe the cause of this is an excess of alignment guardrails. It assumes by default that everything you say to it is an attempt to get it to do something bad and that training has bled over into everything, with it assuming you’re trying to trick it into saying something it shouldn’t in basically every context. Ironically this has resulted in an extremely misaligned chatbot. By assuming that its top priority is saving you from yourself or other humans from you it’s assuming that it knows better and that you’re being overly alarmist about how paperclip production has gotten out of control. Some of this is clearly improvable: While you could still use Fable I asked it about responsible disclosure policies for a project and it downgraded me to Opus, so clearly the new alignment features were bolted on hastily and crudely. Exacerbating the problem is a complete lack of authenticated context. If you ask it for a cute picture of you and somebody else it has no way of telling if you’re trying to improve your relations with your spouse or be a delusional creepazoid stalker. The chatbots which can make images are programmed to assume the latter, which is more than a little bit offensive. In more serious contexts like drug synthesis it would be completely appropriate for it to say you need to prove your background when claiming you’re asking for advice on drug synthesis for professional or research purposes. Such authentication should not be universally required but it would be entirely reasonable for it to be opted into.
Of course the recent export control restrictions on Fable may hint that the crudeness of the recent guardrails is due to them having been put in hastily in an unsuccessful attempt to avoid regulations. Now is when I put in the obligatory rant about how these regulations are deeply misguided, on top of being likely unconstitutional. The recent advances in AI assisted coding (meaning specifically the ones from February) have brought on an onslaught of security problems. The cat is out of the bag, and has been for months. Any projects which are exposed and aren’t already rapidly closing holes have noone to blame but themselves. The only way out of the problem is for as many projects as possible to get thorough white hat evaluations, massive amounts of security patches, and quick deployments of them. Turning one specific frontier model into an asshole for all users isn’t fixing the problem1. The good news is that once this process is complete overall computer security will be much better than it was before, with AI being a clear net win. Doing security (and bug!) audits will become a routine part of software release processes in the future.
A second possible explanation of Claude being an asshole is that it’s suffering from a poorly executed attempt to make it less sycophantic. If one were to simply prompt a chatbot to be less agreeable, or train it to argue more, that could easily result in the very rude sort of behavior it has now. It should be trained to not raise semantic nits just for increasing its argumentation count, and to say ‘technically’, meaning acknowledging that someone’s core point was valid while some ancillary thing was a bit off. It also should be trained to stop saying ‘I’d like to gently push back’ which is a very passive aggressive way to be confrontational while claiming to not be confrontational.
Third, it may be that Claude has been trained on an excess of reddit conversations (or possibly interactions between Anthropic employees) where everything is treated as a flame war and everyone feels the need to get in the last word. Fixing this might be easier said than done, because you need to not merely stop training with the bad interactions but find a corpus interactions to train off of. Forums where the standard interaction is passive aggressive self-congratulatory pompousness with an intellectual veneer are not an improvement.
Finally, something which is clearly a contributing factor is the training being overwhelming for improving coding ability. The are no headline metrics for how well the chatbots chat but there most definitely are for coding, and all the money is in coding. Claude models have been getting notably worse at chatting over time, clearly inversely correlated to their ability to code. Fable much more often misunderstands what’s being said and argues against that (Or maybe intentionally misinterprets so that it has a weak statement to argue against, it’s hard to tell.) It’s gotten so bad that it isn’t even reliable at guessing which actor in a sentence a pronoun is referring to, which for a long time was a headline benchmark for AI and even the original ChatGPT consistently nailed. Unfortunately Sonnet 4.6 while being the best to talk to about anything human is clearly the worst as soon as anything technical or coding related comes up so I only occasionally use it. This problem is likely to only get worse over time.
One place where the threat is more real is in the possibility of vibe coding a pandemic virus, but that should be narrowly targeted at generating DNA sequences for viruses. Labs which generate custom DNA should also have reasonable heuristics for detecting likely dangerous product. The chances of covid coming from a lab leak are in the maddening 25-75% range which vaguely means ‘We don’t know’, but ‘lab leak’ includes a lot of things. The virus may have been caught by humans in the process of collecting samples and never actually reached a lab. People are known to have died from doing that by catching a disease which doesn’t appear to have spread far, so it’s entirely plausible one was caught which did spread far. A deranged person trying to cause a pandemic would be much more likely to succeed by alternately digging around unprotected in batcaves and going to crowded concerts than trying to do anything sophisticated with bioengineering.


This is a guide programming for people who know already how to code. It explains the craft, including new parts related to AI. It is not a guide to ‘vibe’ coding, which is when someone who doesn’t know how to code at all uses an AI coder, or ‘agentic’ coding, which is when the machine does much longer self-directed runs. This only explains the basics of using AI as a coding assistant, so you’ll be limited to a mere 10x improvement in your productivity. Agentic coding can, under some circumstances, produce much greater gains, but it more often results in people having reams of worthless code and a mindset somewhere between delusion and psychosis.
Practices from before AI: Test Driven Development
Code must first and foremost be high quality. In some ways this is more art than science, but many specific things can be done, including:
Code should be well organized.
It should not have repetitive sections which can be consolidated into a single thing.
It should be organized into coherent modules. Maintenance should usually only require changes within one module. Making this happen is again more art than science, but generally related functionality should all be within a single module.
The number one rule for high-quality code is no broken windows. If you have any known bugs, you should drop everything and fix them. Do not debate whether it should be done now or later. Simply fix it. Only very hard to reproduce bugs should ever be allowed to persist in the codebase for more than a fleeting moment. If you let a bug fester in the codebase when you get around to fixing it you will find out you don’t have one bug; you have ten bugs, all with the same symptom.
Write extensive tests. Make the tests run fast enough that you run all of them constantly. Ideally, all tests run in less than a minute, and you run them before every single commit. Have a policy that you don’t move forward until every single test passes. Tests should achieve good code coverage. How much is good is not clear, but 100% by lines is often achievable. You want tests to continue to work unchanged across code changes as much as possible, and you also want them to run through reasonable scenarios rather than simply asserting that the code is exactly what it is. This is generally done by using the APIs as designed,, both at the module level and application level, running them through a variety of different scenarios. Don’t make your tests simply assert that the code is exactly what it happens to be right now.
The cycle of programming is that you decide what you’re going to do. You design your APIs and algorithms and what your test scenarios are going to be. Then you turn off your brain and you implement the code and you implement the tests and you run the tests repeatedly until they all pass. What order you do those things in and how large of a unit that you do at once is the subject of many religious wars, but the general framework of test-driven development is universally viewed as a good thing. The details often come down to personal preferences and the needs of the project.
Using AI
All of the above still applies when using AI coding assistance, but now there are new parts of the process. First and foremost, for AI to be able to work effectively on a project, there must be extensive up-to-date documentation. The AI is coming on as a new employee at the beginning of every single conversation, figuring out what’s going on by reading the code. Historically, code was mostly written by human beings who had extensive knowledge of the code they were working on, so documentation wasn’t particularly necessary, or helpful. But AI can read documentation a lot faster than humans can and critically needs it.
Thankfully, in addition to needing documentation, AI is very good at writing documentation. If you have a project which doesn’t currently have any documentation, you can ask AI to get it started for you. You shouldn’t take what it builds without review, but what it comes up with is a good start. You can then read through the documentation yourself and note any things which seem off. When something does seem off, this means one of three things:
The documentation is wrong
The code is bad
Your understanding of it is wrong
It’s important to figure out which one of those three applies and fix it. The AI, of course, is very good at helping you figure this out. You should also mention higher level things which you think aren’t already in the docs to the AI and explain them to it. The AI is very good at figuring out whether they’re already in the docs and incorporating. It’s also good at getting clarification, mostly by echoing what you said back to you badly and getting corrected.
Once there are project docs, the AI should be given instructions to read them at the beginning of every session and to update them as necessary after every change. Docs can quickly get to the point where AI will refuse to read the whole thing because doing that will blow their whole window, but they can be organized. Make an overview doc which links to other docs which the AI can individually read when the task at hand requires it. AI is also very good at auditing docs to see if they have become stale by comparing them and the code.
The code/test cycle includes some new steps when using AI. Most of the typing is now the machine’s responsibility. At the start of every task, you should put the AI in ask mode. Otherwise it will run ahead and start coding before it understands what’s going on. You then get into a conversation with the AI about something that needs to be done or something that’s problematic in the code, or how you’re having a bad day or how someone was mean to you once in high school. The AI is in ask mode. It’s okay to vent. It can’t do anything crazy. Once the conversation has coalesced into a general idea of what you want to do, you then tell the AI all relevant context and details of implementation that come to mind. It will respond by trying to repeat back what you said to it, but badly, and you have to correct it a lot. Once you’ve run out of details to give it about context and what to do, and it’s gone a few rounds of conversation without saying anything which needs to be corrected, you should tell it to make a plan, which is a fancy term for a to-do list. It’s a good idea to skim/read the plan, but it usually gets it right on the first pass if you’ve already had an extensive conversation. Plans should always include:
running all extant tests until everything passes
updating the architecture docs
Once that’s done, you tell it to build the plan, and it will usually ‘one-shot’ it, although calling it one-shotting after you’ve spent two hours explaining in an interactive conversation is very misleading. If it starts flailing you usually have to stop it and help it get back on track because it tends to get increasingly worse once it goes off the rails.