This feed omits posts by rms. Just 'cause.
In honor of this important anniversary, I downloaded the original Flash SWF file from Internet Archive, played it using Ruffle in a full-screen window, and replaced the audio with the original MP3 of "Invasion of the Gabber Robots" by The Laziest Men on Mars. So this is probably the highest fidelity encoding possible, without going back to the original forum GIFs.
Make your time.

As described previously, the Linux kernel security team does not identify or mark or announce any sort of security fixes that are made to the Linux kernel tree. So how, if the Linux kernel were to become a CVE Numbering Authority (CNA) and responsible for issuing CVEs, would the identification of security fixes happen in a way that can be done by a volunteer staff? This post goes into the process of how kernel fixes are currently automatically assigned to CVEs, and also the other “out of band” ways a CVE can be issued for the Linux kernel project.
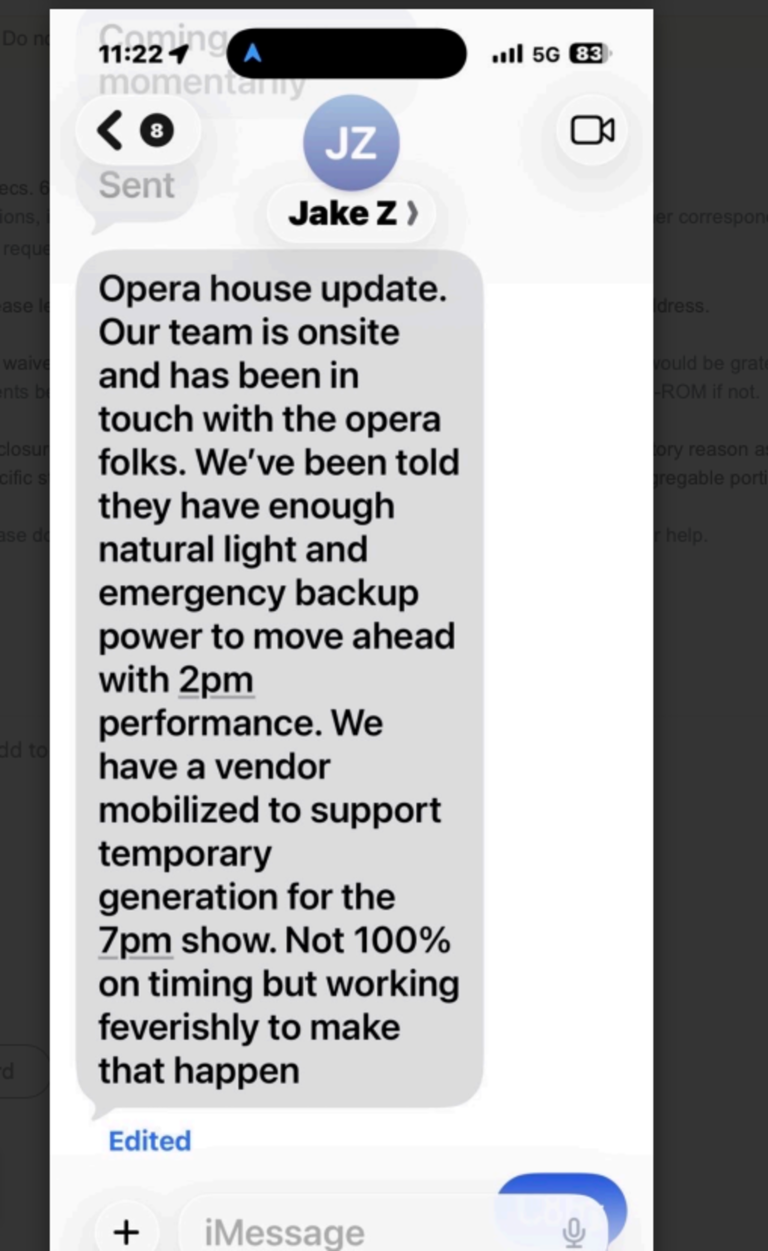
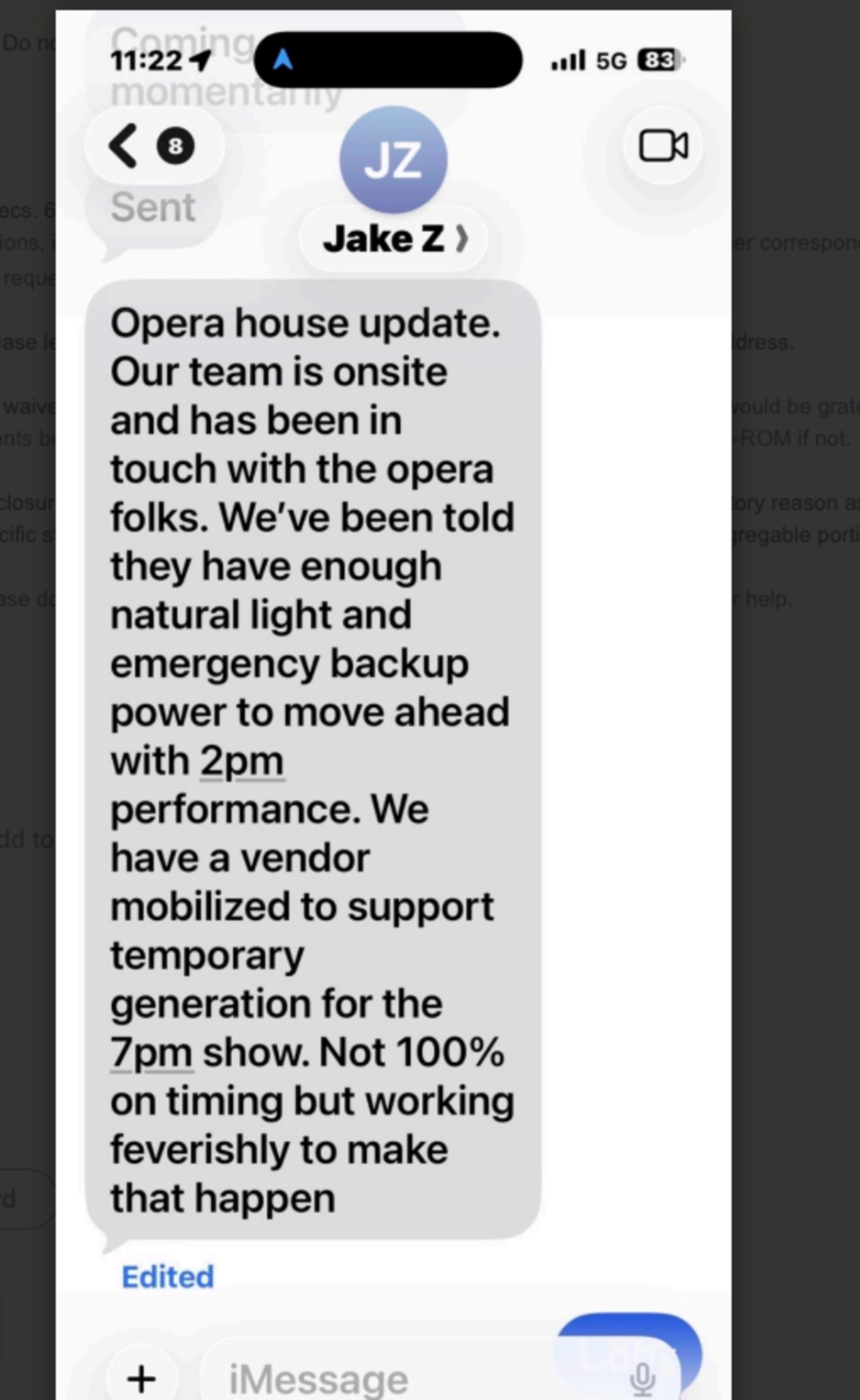
Not mentioned at the hearing: The mayor's teenage daughter, Taya Lurie, was cast in the starring role of Clara at the matinee performance that Sunday.
During stunning testimony before the Board's Public Safety Committee, Supervisor Bilal Mahmood asked PG&E CEO Sumeet Singh why the utility had chosen to help the arts venue while so many other San Francisco sites were without power.
"You prioritized the opera, where no one is living, to restore service, before you prioritized restoring service in communities and seniors living in [single room occupancies]," said Mahmood.
"We did not make that decision on our own accord," Singh replied. "We were requested by the mayor to provide temporary generation to that specific location. And we responded to that."
Singh said 10% of affected PG&E customers were still experiencing blackouts when the mayor made his request.
The mayor's comms team went ballistic and a couple days later, the PG&E CEO recanted and said: Oh, that thing that I quite clearly stated, that was a "misunderstanding". Uh huh.
So the interesting thing here is not that our oligarch mayor is both corrupt and bumbling -- I mean, water is wet -- but that PG&E chose to throw him under the bus like that. Statements like that, from people like that, about people like that, don't happen off the cuff. With the renewed and increasing calls to Eminent Domain PG&E, you'd think that PG&E would want SF's mayor on their side. This suggests that they think they just don't need him.
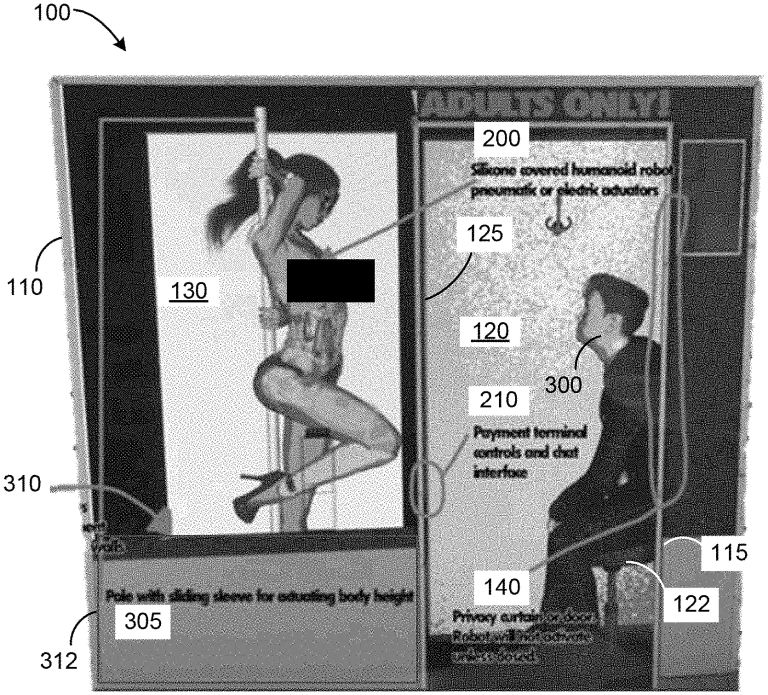
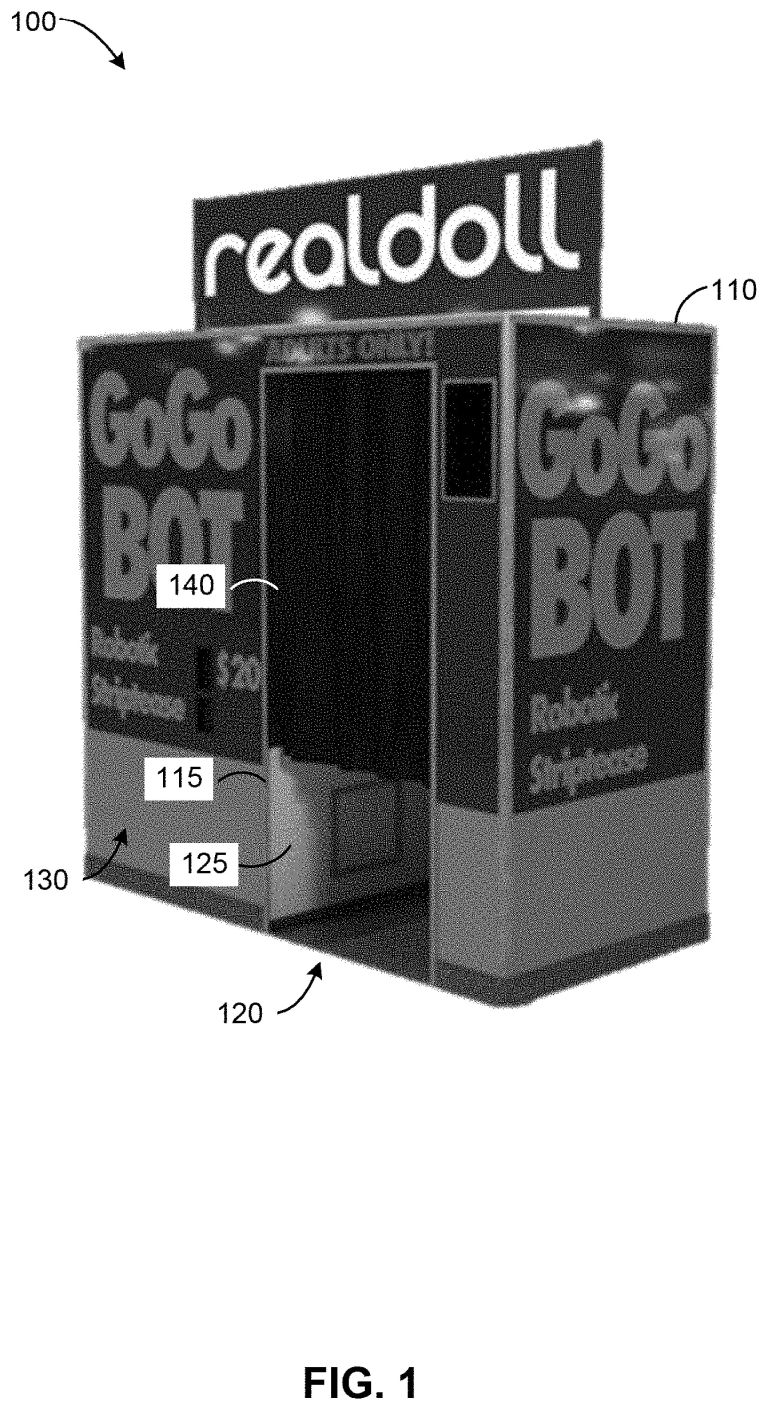
A booth having a housing enclosing a viewing station opposite an entertainment station; a robotic entertainer disposed within the entertainment station, the robotic entertainer having a humanoid appearance and comprising a plurality of actuators; and a computing system coupled to the plurality of actuators and configured to control the actuators so to move the robotic entertainer in accordance with a performance.
Previously, previously, previously, previously, previously, previously, previously, previously, previously, previously, previously, previously.
Previously, previously, previously, previously, previously, previously, previously, previously, previously, previously, previously, previously, previously, previously.
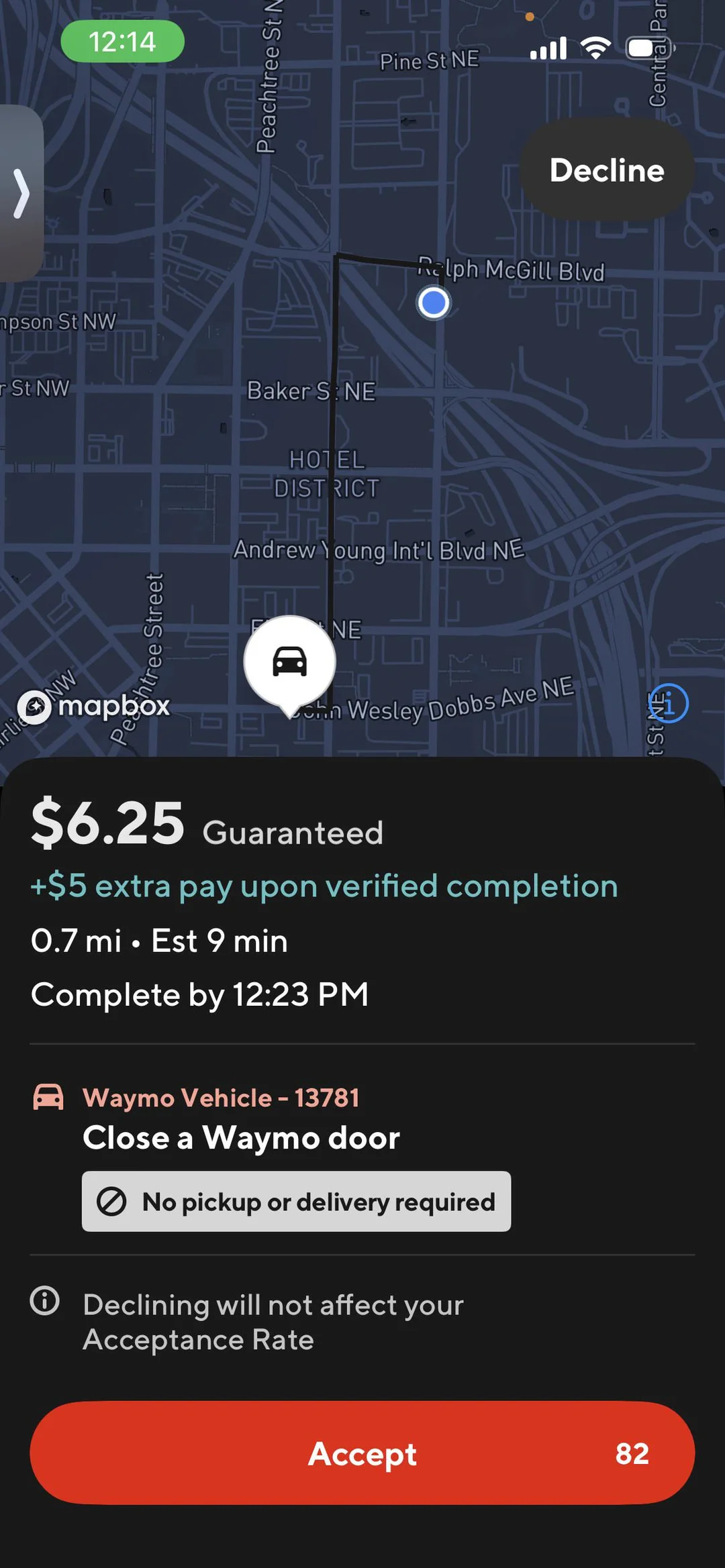
Waymo, Google's autonomous vehicle company, and DoorDash, the delivery and gig work platform, have launched a pilot program that pays Dashers, at least in one case, around $10 to travel to a parked Waymo and close its door that the previous passenger left open.
Previously, previously, previously, previously, previously, previously, previously.

The "very poor," as well immigrant communities and the very young and old, the amendment read, "fall outside the non-cash financial system." [...]
Nationwide, those levels are decreasing, but remain significant. A survey conducted by the FDIC found that in 2023, Black and Latino households were overrepresented in the unbanked population, with 10.6 percent of Black and 9.5 percent of Latino households in the U.S. were unbanked, down from 17 and 14 percent in 2017.
Today, approximately 4 percent of San Francisco households are "unbanked," or do not have a checking or savings account, and nearly 14 percent are "underbanked" -- have bank accounts but primarily use cash or use check cashers or money orders. [...] "These residents are often the most financially vulnerable and can face higher costs and barriers in everyday transactions," Manke said.
The destruction of cash is part of the advertising panopticon agenda. Paper money doesn't have a utm_source on it so it is useless.
Let us also keep in mind that this "vocal contingent of local business owners" are the same business geniuses who are always, always certain that a bike lane will ruin them.

My vendetta against tape on the walls is endless. I just think it looks really tacky. Plus, one of the things about paper that it is famous for is always showing the same thing. Whereas these screens have all kinds of complications. (In watchmaking, anything that a timepiece does beyond showing hours, minutes and seconds is called a "complication", and I love that term.)
For example, they are sensitive to the room they are in and the genres of the show that is currently happening, so if it's a metal night, they're going to show flyers for other metal shows much more often. They are likewise skewed toward showing shows happening sooner than later.
And another recent complication is the dancing QR codes. I put a bunch of work into making the underlying URLs as short as possible so that the QR codes have big chunky pixels that you can scan from across the room (or from space.)
We also use a couple of screens in the Pizza checkout lane to hype our appetizers.
In summary, digital signage is a land of complications.



Please enjoy jwz mixtape 257.

The one thing the longevity-vampire community has not yet learned from Dracula is operational security.
Dracula operated in silence for centuries. He didn't have a podcast. He didn't track his erection quality on a public dashboard. He didn't appear on Netflix. He understood that the fundamental rule of being a vampire is: don't talk about being a vampire.
Johnson, Thiel, and their cohort have broken this rule comprehensively. Whether this represents a new era of transparency or a catastrophic strategic miscalculation remains to be seen.
Previously, previously, previously, previously, previously, previously, previously, previously.
When playing melodies the effects of microtonality are a bit disappointing. Tunes are still recognizable when played ‘wrong’. The effects are much more dramatic when you play chords:
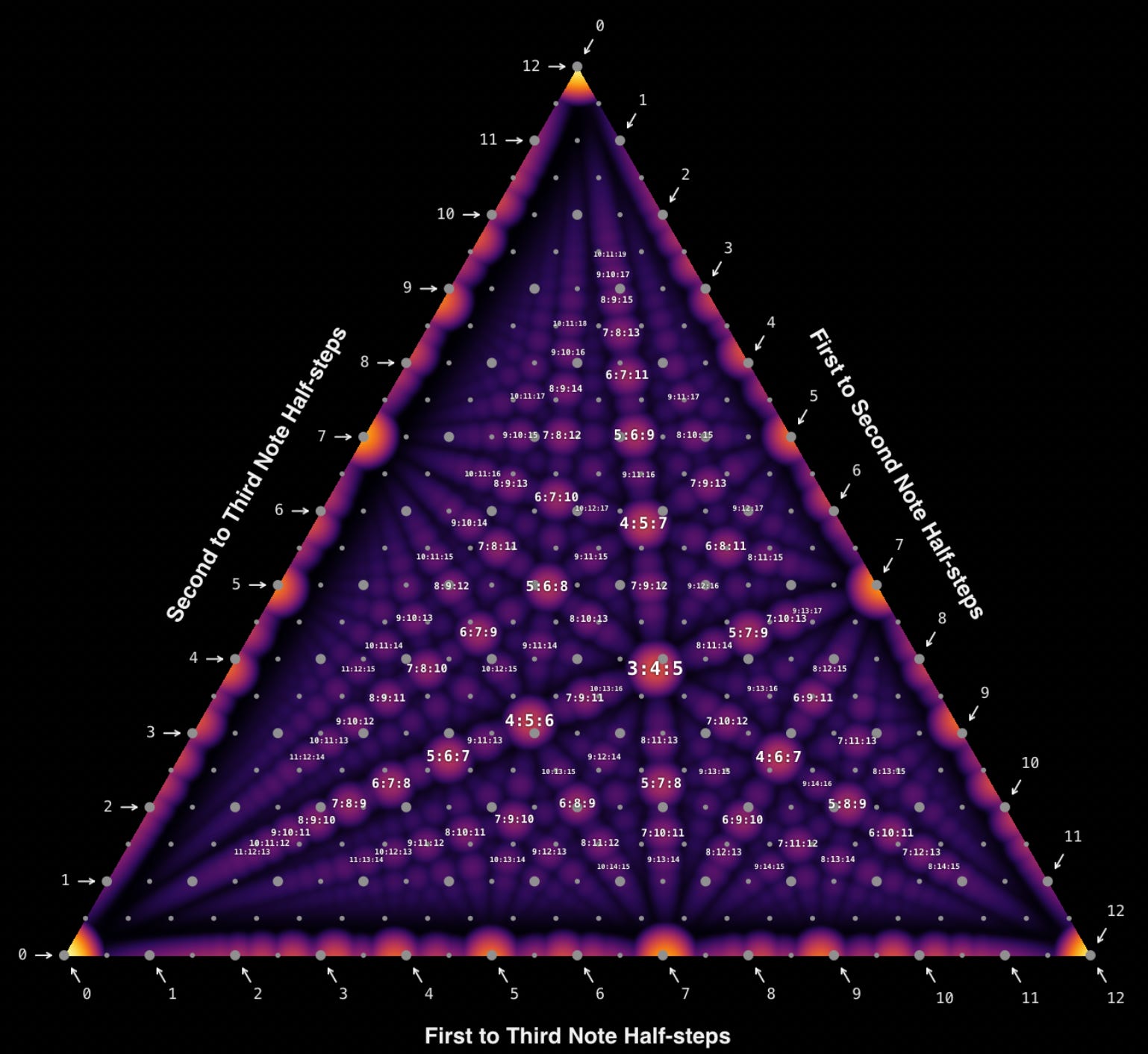
You can and should play with an interactive version of this here. It’s based off this and this with labels added by me. The larger gray dots are standard 12EDO (Equal Divisions of the Octave) positions and the smaller dots are 24EDO. There are a lot of benefits of going with 24EDO for microtonality. It builds on 12EDO as a foundation, in the places where it deviates it’s as microtonal as is possible, and it hits a lot of good chords.
Unrelated to that I’d like to report on an experiment of mine which failed. I had this idea that you could balance the volumes of dissonant notes to make dyads consonant in unusual places. It turns out this fails because the second derivative of dissonance curves is negative everywhere except unity. This can’t possibly be a coincidence. If you were to freehand something which looks like dissonance curves it wouldn’t have this property. Apparently the human ear uses positions where the second derivative of dissonance is positive to figure out what points form the components of a sound and looks for patterns in those to find complete sounds.

Here’s the story of a legendary poker hand:
Our hero decides to play with 72, which is the worst hand in Holdem and theory says he was supposed to have folded but he played it anyway.
Later he bluffed all-in with 7332 on the board and the villain was thinking about whether to call. At this point our hero offered a side bet: For a fee you can look at one of my hole cards of your choice. The villain paid the fee and happened to see the 2, at which point he incorrectly deduced that the hero must have 22 as his hole cards and folded.
What’s going on here is that the villain had a mental model which doesn’t include side bets. It may have been theoretically wrong to play 72, but in a world where side bets are allowed and the opponent’s mental model doesn’t include them it can be profitable. The reveal of information in this case was adversarial. The fee charged for it was misdirection to make the opponent think that it was a tradeoff for value rather than information which the hero wanted to give away.
What the villain should have done was think through this one level deeper. Why is my opponent offering this at all? Under what situations would they come up with it? Even without working through the details there’s a much simpler heuristic for cutting through everything: There’s a general poker tell that if you’re considering what to do and your opponent starts talking about the hand that suggests that they want you to fold. A good rule of thumb is that if you’re thinking and the opponent offers some cockamamie scheme you should just call. That certainly would have worked in this case. This seems like a rule which applies in general in life, not just in Poker.

Let’s say you wanted an offroad vehicle which rather than being a car-shaped cowboy hat was actually useful for camping. How would it be configured?
The way people really into camping approach the process is very strange to normal people and does a negative job of marketing it. You drive to the campground in a perfectly good piece of shelter and then pitch a tent. Normal people aren’t there to rough it, they’re there to enjoy nature, and sleeping in one’s car is a much more reasonable approach.
To that end a camper vehicle should have built-in insulation, motorized roll-up window covers, and fold-up rear seats. You drive to the campground, press the button for privacy on the windows, fold up the seats, and bam, you’re all set.
It should have a big electric battery with range extender optimized for charging overnight. The waste heat during the charging process can keep the vehicle warm while you sleep in it.
Roughly 8 inch elevation off the ground and a compliant suspension designed for comfort on poorly maintained roads rather than feeling sporty.
Compact hatchback form with boxy styling. Hatchbacks are already boxy to begin with and a flat front windshield works well with window covers so it’s both functional and matches the aesthetics.
Available modular fridge, induction plate, and water heater. With custom connectors to the car’s battery the electric cooking elements could ironically be vastly better than the ones in your kitchen.
Unfortunately having a built-in shower or toilet is impossible in a compact but the above features might be enough to make it qualify as a camper van which you’re allowed to live in. They’d at least make it practical to inconspicuously live in one’s car and shower at a gym.
Leela Odds is a superhuman chess AI designed to beat humans despite ludicrous odds. I’m a decent player and struggle to beat it with two extra rooks. It’s fun doing this for sheer entertainment value. Leela odds plays like the most obnoxious troll club player you’ve ever run into, more like a street hustler than something superhuman. Obviously getting beaten in this way is also humiliating, but it also seems to teach a lot about playing principled chess, in a way which raises questions about objectivity, free will, and teaching pedagogy.
Most computer chess evaluations suffer from being deeply irrelevant to human play. When decently strong humans review games with computer evaluation as reference they talk about ‘computer lines’, meaning insane tactics which no human would ever see and probably wouldn’t be a good idea for you to play in that position even after having been told the tactics work out for you in the end, much less apply to your more general chess understanding. There’s also the problem that the only truly objective evaluation of a chess position is one of three values: win, lose, or draw. One move is only truly better or worse than another when it crosses one of those thresholds. If a chess engine is strong enough it can tell that a bunch of different moves are all the same and plays one of them at random. Current engines already do that for what appear to be highly tactical positions which are objectively dead drawn. The only reason their play bears any resemblance to normal in those positions is they follow the tiebreak rule of playing whichever move looked best before they searched deeply enough to realize all moves are equivalent
So there’s the issue: When a computer gives an evaluation, it isn’t something truly objective or useful, it’s an evaluation of its chances of winning in the given position against an opponent of equal superhuman strength. But what you care about is something more nuanced: What is the best move for me, at my current playing strength, to play against my opponent, with their playing strength? That is a question which has a more objective answer. Both you and your opponent have a probability distribution of what moves you’ll play in each position, so across many playouts of the same position you have some chance of winning.
This is the reality which Leela Odds already acknowledges. Technically it’s only looking at ‘perfect’ play for its own side, but in heavy odds situations like it’s playing the objectively best moves are barely affected by the disadvantaged side’s strength anyway because the only way a weaker player can win is to get lucky by happening to play nearly perfect moves. And here we’re led to what I think is the best heuristic anyone has ever come up with for how to play good, principled, practically winning chess: You should play the move which Leela Odds thinks makes its chances against you the worst. The version of you playing right now has free will can look ahead and work out tactics but the version of you playing in the future cannot and is limited to working out tactics with only some probability of success. You can learn from advice from the bot about what are the most principled chess moves which give you the best practical chances assuming the rest of the game will be played out by your own not free will having self. Everybody has free will but nobody can prove it to anybody else, not even themselves in the past or the future. The realization that your own mental processes are simply a probability distribution does not give you license to sit around having a diet of nothing but chocolate cake and scrolling on your phone all day while you wait for your own brain to kick in and change your behavior.
Philosophical rant aside, this suggests a very actionable thing for making a better chess tutor: You should be told Leela Odds’s evaluation of all available moves so you can pick out the best one. The scale here is a bit weird. In an even position it will say things like your chances of winning in this position are one in ten quadrillion but if you play this particular move it improves to one in a quadrillion. But the relative values do mean a lot and greater ratios mean more so some reasonable interface could be put on it. I haven’t worked out what that interface might be. This approach may break down in a situation where you’re in an objectively lost position instead of an objectively won one and you should be playing tricky troll moves yourself. That seems to matter less than you might think, and could be counteracted by reverting to a weaker version of Leela Odds which can’t work out the entire rest of the game once it gets into such a position.
So far no one is building this. Everybody uses Stockfish for evaluation, which suggests a lot of lines you could have played if you were it, but of course you’re not, and is overly dismissive of alternative lines that would have been perfectly fine against your actual non-superhuman opponent. Somebody should build this. In the meantime if you want to improve your chess you’re stuck getting humiliated by Leela Odds even when you’re in what seem to be impossible to lose situations.

SR-17018 is a novel drug which is getting increasing underground usage for quitting opioids. It is technically an opioid itself but produces an amount of euphoria which is somewhere between barely noticeable and completely nonexistent. While taking it people don’t get withdrawal symptoms from Fentanyl but their Fentanyl tolerance fades at about the same rate as if they were going cold turkey without the SR-17018. People have been successfully using it to quit opioid addictions and even keeping a stash of it around in case they relapse, which is bizarre behavior for usually addicts. Usually if there are any opioids around they’ll take them and it will cause a relapse, so this stuff must really not be much fun or addictive. Opioids for opioid quitting has a bad reputation because of Methadone, but swapping Buprenorphine for Fentanyl is a big improvement and SR-17018 seems to be truly good for cessation. Unfortunately because it’s technically an opioid and there hasn’t been any movement on getting it approved for cessation purposes (it was originally studied as a painkiller which it’s unsurprisingly not very good at) most likely it will get shoved into schedule 1 at some point, sanity and reality be damned.
Varenilicline is a good smoking cessation drug but causes nausea in some people. The obvious fix would be to give patients Ondansetron with it. This has been suggested but doesn’t seem to have been tried, not even a case study. There seem to be two problems here: The drugs in question are generic and there’s no incentive to develop treatment improvements which are very cheap, and there’s a general view that any treatment of addiction is super scary and the patients should have to suffer, even for fairly safe drugs with no reason to think they’ll have a bad interaction.
Sodium Oxybate is about to get orphan drug status, for the second time, for the same drug, which is already making more than a billion dollars a year and was neither discovered nor characterized by the company which got the orphan drug status the first time. Pharma has the deeply broken structure that exclusivity periods are the only form of reward for research but a start to fixing it would be to make it that formulation changes are both much easier to get through and give much less exclusivity. A bare minimum start to that would be to clarify that orphan drug status was never meant to apply to formulation changes. It would also be good to make sectors which are already making massive profits not qualify as orphan any more and to reduce the exclusivity period for formulation patents in general, with time release formulas and salt changes handled as specific special cases.
People are unsure of what the inevitable huge disruptions AI will bring to software will eventually be, but one thing which is clear is that enterprise software as a service will be hard hit. The industry is producing products which are too awful, and is too bottlenecked on software development costs, to not be completely upended.
The way that industry works currently is that there’s generally a single dominant player in each niche which has a codebase with a million features ten of which are important. The problem is that every one of their customers uses twenty features: The ten which are important to everyone, and ten others which are important to them specifically. And which ten long tail features each customer cares about have very little correlation to each other.
It’s clear that million dollar a year saas contracts are going away. It’s becoming way too practical for customers that large to write their own bespoke solutions from scratch and wind up with something which sucks less. But that doesn’t mean everybody is going to write everything completely from scratch. Most likely there will be open source solutions for most problems which only have the ten big features and everybody vibe codes customizations for their their own deployment.
The open source business model for this is time honored and straightforward: The company maintaining the open source version also has a service where you pay for deployment. But now it’s even better, because they’ll have a vibe coding interface which is super trained on ten thousand other customizations of their codebase. They’ll likely even sneak in some human intervention in the background to help with rebasing when a new release of the base product comes out. And they’ll have a license which allows and all customizations to be upstreamed if the maintainers want them to be. There will probably be niche consultancies which specialize in helping companies do customizations of specific products but that won’t be done in house by the maintaining company because saas shops will still try to maintain high capital efficiency.
The whole saas industry is much more vulnerable than people realize. You could get me to switch off Jira just by making a comparable product which had page load times out of this century. And vibe coding will absolutely be at the core of the new way of doing things.
This video caught my fancy so here are my thoughts on improving the design. There seems to be a lot of things which can be done which should make big improvements but consider everything in this post speculative spitballing. Anyone who wants to improve on this mechanism is free to try my ideas.
Technically it’s a bit wrong to say this mechanism has ‘no moving parts’. It does have moving parts, they’re just air bubbles which are being captured on the fly and hence aren’t subject to wear. The problem is that air bubbles don’t like behaving.
Starting with where the water comes in:
The mechanism in the above video is cheating a bit because the pump getting the water into the top is aerating it. A proper mechanism should have a way of getting air into the water when it’s coming in slowly and steadily. In particular it should have a mechanism for being able to recover if the mechanism as a whole ever gets overflowed so it isn’t stuck with no bubbles in it forever. The simplest mechanism for this is to have a section of the pipe going down which has holes in the sides. As long as water is flowing fast it will pull air bubbles in through the holes. If it gets backlogged water will escape through the holes and can be directed to the exit, making room for air to be let in. The ideal size and spacing of the holes is unclear. If the mechanism were big enough it would probably improve things a lot to split across multiple pipes which have air intake holes to pull more bubbles in. It might also be a good idea to make a whirlpool and stick a pipe in the middle to help the air go down but that gets complicated.
Once bubbles are captured the downward pipe should be split into a bundle of straws to keep the bubbles from coalescing and forcing their way upwards. The ideal diameter of the straws is probably somewhat dependent on their length but should be small enough that surface tension makes water form plugs. The length of the downward pipe in the above model seems to be way too long. It appears to be that this is being done to make the pulsing effect happen but there’s a better way of doing that which I’ll get to.
The intake for the air bubbles should come from the bottom of the chamber where the pumping upwards happens. That should lead upwards to a manifold which is a short pipe with a horizontal cap at the top with holes in it, all kept under water. Air will then build up in the pipe and result in a steady stream of bubbles coming out of the holes. The size and depth of the holes as well as the material they’re made out of and the width of the pipe relative to the rate of air coming in all affect the nucleation of bubbles. What should happen is that bubbles of a reasonably consistent size come up at a reasonably consistent rate in a nice steady stream instead of the chaos you see above. There’s probably a range of possible sizes and rates of bubbles which are possible and that needs to be studied.
Instead of a single pipe going upwards there should be a bundle of straws. The bottoms of the straws should splay out and have tapered inlets with a one to one correlation with the holes in the manifold so the bubbles from that hole go directly into that straw and push the water upwards. The ideal number and diameter of the straws is very dependent on how far the water is being pumped, how quickly the air is coming in, and what they’re made out of. They should be thin enough that surface tension causes water in them to form a plug and makes bubbles force the water upwards. The idea is to make the water flow up slowly and steadily, with the upwards force of the bubbles just barely able to force it to the height it’s being pumped to, without wasting any energy on the momentum from those pulses. Maybe this shift in emphasis makes the whole thing technically a different mechanism.
At the top the straws should flare away from each other so the water going out of one straw doesn’t fall into its neighbors.
Hopefully these changes can improve the efficiency of the system from awful to merely bad. You’d still only use it when you care less about efficiency than low maintenance or quiet or specifically want aeration. Using all those straws will reduce how well it works on water containing particulates.


AI slop has been doing real damage to bug bounty programs. My company has expended significant engineering resources wading through the garbage. The bug bounty platforms do a decent job of filtering but some things are simply outside their expertise and need to be forwarded along.
This is an unfortunate turn of events. A few years ago false security reports were not terribly onerous and even when they happened they were usually someone earnestly thinking they’d found something. Even when the person was horribly confused they were usually serious enough that it felt right to try to encourage them.
To be clear, there’s nothing wrong with using AI as a tool for searching for bugs. If someone finds a completely legitimate security problem using AI as part or all of their toolchain and submits a properly formatted report they are free to claim it. I would give the benefit of the doubt and think that even the mostly bogus reports we’re getting are from people who are doing nontrivial amounts of work to train models specifically for bug finding with their own filters and processing to maximize chances of success. They must be submitting because they have some real hit rate.
The problem is that the burdens of evaluating false positives are borne entirely by the entity handing out the rewards. This wasn’t a problem back when submissions were done manually because back then having an instance of a report which was probably wrong but having a 1% chance of success was rare, and the costs of validating such things properly were small compared to the costs of coming up with the possible attack in the first place, and if you did submit and got a follow-up question answering it was a real burden on the submitter. Now none of those things apply so there’s a flood of low probability but worth a shot reports.
The solution to this I’d like to propose is something which would have been completely verboten a few years ago but now unfortunately may be necessary: Anyone submitting for a bug bounty should have to put down a deposit. Even a relatively low amount like $100 would probably make a huge difference. Ideally there’s a policy in place that there’s a generous refund program that submissions which are at all earnest get their deposit back even if they’re mistaken. If that causes too much arguing about what’s ‘earnest’ it may be necessary to make it a fee rather than a deposit, but I think it’s always legally okay to have a policy of returning such fees as long as it’s made clear up front that it’s completely discretionary on the part of the evaluator.
No doubt this suggestion will make some people very upset because it completely violates the traditional ethos of how bug bounties work. It would also create an opportunity for scammers to set up bug bounties for fake projects with lots of security holes which they then pocket the fees for submissions on and refuse to pay out any owed bug bounties. These are real problems and there are mitigations but rather than diving into the weeds I’d just like to say I know and I’m sorry but the situation is sufficiently out of control that this is probably necessary. I’m suggesting this publicly so I can be the bad guy who other people point to when they suggest it as well.